Notebook
This is a personal notebook. See repo here. Let's see how often I can keep this updated...
How to update my note:
https://rust-lang.github.io/mdBook
And take a look at Markdown Help for some hints.
mdbook serve --dest-dir docs --open- Edit content
- Then perhaps build again
mdbook build --dest-dir docs - Then push
Some hidden code here
use warp::Filter; #[tokio::main] async fn main() { let routes = warp::any().map(|| "Hello, World!"); warp::serve(routes).run(([127, 0, 0, 1], 3030)).await; }
How to add some graphs?
https://github.com/badboy/mdbook-mermaid
And see the Dockerfile in the repo how to make an image that can build the site.
About github page build
This github action peaceiris/actions-gh-pages seems really handy. See the config file here
Note 1
Some random notes that could be useful:
How to make http slides:
https://liufuyang.github.io/http-kv/demo.html
ToDo
Courses to study
Algorithms

Big O notations
Commonly-used notations in the theory of algorithms
| notation | example | provides | shorthand for | used to |
|---|---|---|---|---|
| Big Theta | \( \Theta (N^2) \) | asymptotic order of growth | \( {1 \over 2} \ N^2 \) \( 10 \ N^2 \) \( 5 N^2 + 2 N \log N + 3 N \) | classify algorithms |
| Big Oh | \( O (N^2) \) | \(\Theta(N^2) \) and smaller | \( 10 \ N^2 \) \( 100 \ N \) \( 2 N \log N + 3 N \) | develop upper bounds |
| Big Omega | \( \Omega (N^2) \) | \( \Theta(N^2) \) and larger | \( {1 \over 2} \ N^2 \) \( N^5 \) \( N^3 + 2 N \log N + 3 N \) | develop lower bounds |
| Tilde * | \( \sim 10 \ N^2 \) | leading term | \( 10 \ N^2 \) \( 10 \ N^2 + 22 N \log N \) \( 10 \ N^2 + 2 N + 37 \) | provide approximate model |
* A common mistake is interpreting Big-Oh as an approximate model Tilde.

Stack and Queue
Two major implementations
- Linked list impl
- Array impl
which can both implement stack and queue.
Linked list impl
For stack or queue, a single direction link list will do,
so only need a head point to the head node, and a tail point to the tail node.
(head) -> (a,) -> (b,) -> (c,)
(tail) - - - - - - - - - - ^
A simple unsafe Rust implementation could use structures like:
#![allow(unused)] fn main() { pub struct Node<T> { element: T, next: Option<Box<Node<T>>>, } pub struct LinkedList<T> { head: Option<Box<Node<T>>>, tail: *mut Node<T>, } }
More code can be see here on my own bad Rust stack/queue implementation
pushadd node viahead;enqueueadd node viatail;popordequeue, just take out nodes fromhead.
Or in short adding on both ends, removing from head only.
Array impl
0 1 2 3 4 5 6 7
[__, __, a, b, c, __, __, __,]
(head) ---^
(tail) - - - - - - - ^
pushorenqueue, just add viatail;popremoves nodes fromtail;dequeueremoves fromhead;
Or in short adding from tail only, removing from both ends.
Other trivial details:
- When reaching the end while adding, increase capacity by factor of 2;
- When
tailless than 1/4 of capacity, can reduce capacity by 1/2 of current capacity, to save space; - In Java, when removing element from the list, besides change
head and tail values, also set
nullto the array so to let those removed nodes can be garbage collected later.
Dequeue - a double-ended queue
Dequeue -a double-ended queue or deque (pronounced “deck”)
is a generalization of a stack and a queue that supports adding and removing items from either the front or the back of the data structure.
One type of implementation could be using a double linked list, so both ends can remove nodes.
Another approach (I suppose) could be using two stacks, with either stack implementations mentioned above.
Then one stack is kept as positive while another kept as
negative.
So the deque can probably be implemented as something like:
// add the item to the front
public void addFirst(Item item) {
negative.push();
}
// add the item to the back
public void addLast(Item item) {
positive.push();
}
// remove and return the item from the front
public Optional<Item> removeFirst() {
if (!negative.isEmpty) {
return negative.pop();
} else {
return positive.dequeue();
}
}
// remove and return the item from the back
public Optional<Item> removeLast() {
if (!positive.isEmpty) {
return positive.pop();
} else {
return negative.dequeue();
}
}
Haven't tried to do my homework with the Princeton course,
but hopefully this works. Otherwise the code might later
be at here.
Update: As the homework requires constant worst time so
I used a double linked list to implement it. So I can
just guess now the above idea will work :)
RandomizedQueue
A RandomizedQueue can be implemented with a normal
array implementation queue, plus using Knuth Shuffle
during enqueue operation:
public void enqueue(Item item) {
if (item == null) {
throw new IllegalArgumentException();
}
if (items.length == tail) {
resize(Math.max(items.length, size() * 2));
}
items[tail] = item;
tail++;
swap(tail - 1, StdRandom.uniform(head, tail));
}
Key is on that swap call. Basically the shuffle
idea is very simple, when adding a new item into
the array, then randomly select an item from the
array (including the newly added one) then swap
the newly added one with the selected item.
See code here.
By the way, this Knuth Shuffle idea seems
pretty powerful as it uses linear time for shuffling
a N-th array. Better than make N random floats and
sort them to have a new index list.
Linked list impl vs Array impl
I guess simply put,
linked listis good for constant time operations in the worst case, though slower each time, an uses more space;resizing arrayis in most cases very fast, occasionally slow when resizing, with the claim of adding an element has constant amortized time cost. And less wasted space
Priority Queues (a.k.a Binary heap)
Besides the "linear" array/linked-list type of queue implementation,
Binary heap can also be used to construct
an array representation of a heap-ordered complete binary tree,
which can be used as a special queue where you can always get the most
min (or max) value of a queue. See more about it in the search algorithm
session below.
And it can also be used as a sorting algoritm called
Heap sort. See more notes about Priority Queues here
Use stack/queue for Search Algorithm
One quite useful thing about stack and queue is that
stackcan be used forDepth-First Search(DFS)queuecan be used forBreadth-First Search(BFS)
And Priority queue can be used for even faster search algoritms to
only focus on the most possible directions (the shortest path for example).
See more notes about Priority Queues here
Quite interesting.
It seems that a general "Graph Search" type of problem can be solved by this abstract framework:
agent- entity that perceives its environment and acts upon that environmentstate- a configuration of the agent and its environment;initial state- the state in which the agent beginsactions- choices that can be made in a state, like edges in graphs;ACTIONS(s)returns the set of actions that can be executed in state stransition modelorRESULT(s, a)returns the state resulting from performing action a in state sgoal test- way to determine whether a given state is a goal statepath cost- numerical cost associated with a given pathfrontier- a stack or queue to keep track of the nodes to be explored
Then with a node defined as
a data structure that keeps track of
- a
state - a
parent(node that generated this node) - an
action(action applied to parent to get node) - a
path cost(from initial state to node)
Then a search algorithm can be defined as:
Search algorithm
- Start with a
frontierthat contains the initial state. - Start with an empty explored set.
- Repeat:
- If the
frontieris empty, then no solution. - Remove a
nodefrom thefrontier. (Also using a set to keep track of visitednodes) - If
nodecontains goal state (goal test), return the solution. - Add the
nodeto the explored set. - Expand
node(ACTIONS + RESULTS), add resultingnodesto thefrontierif they aren't already in thefrontieror the explored set.
- If the
For example, in a simple maze search problem, the state of
the node is just the current position, the actions of the
node is just the next possible directions that the agent can go to, leading to the following states.
In a social network problem, for example in the homework's
movie actors degree problem, the state of
the node is just the actor id, the actions of the
node is just the movies this actor performed, which can lead to other state (or actors).
Some example code on the degree problem might look like this.
def shortest_path(source, target):
"""
Returns the shortest list of (movie_id, person_id) pairs that connect the source to the target.
If no possible path, returns None.
Action: movie id
State: person id
"""
start = Node(state=source, parent=None, action=None)
frontier = QueueFrontier()
frontier.add(start)
explored = set()
while True:
if frontier.empty():
return None
node = frontier.remove()
explored.add(node.state)
for action in people[node.state]["movies"]:
for state in movies[action]["stars"]:
if not frontier.contains_state(state) and state not in explored:
child = Node(state=state, parent=node, action=action)
frontier.add(child)
checkNode = child
if checkNode.state == target:
actions_and_states = []
while checkNode.parent is not None:
actions_and_states.append((checkNode.action, checkNode.state))
checkNode = checkNode.parent
actions_and_states.reverse()
return actions_and_states
And normally a queue is used as the frontier in order
to perform Breadth-First Search - which seem to be the
best option for general problems as you want to find the shortest path to the goal.
One variant of the algorithms is a greedy best-first search
A* search: search algorithm that expands node with lowest value ofg(n) + h(n)g(n)= cost to reach nodeh(n)= estimated cost to goal- optimal if
h(n)is admissible (never overestimates the true cost), andh(n)is consistent (for every node n and successor n' with step cost c,h(n) ≤ h(n') + c)
To facilitate a fast way to pick "a lowest value (or highest) from a queue",
a data structure called Priority Queue
can be used as it as uses binary heap to achieve log N order-of-growth for
both queue insert and queue delete operation.
Another variant of this type of algorithm is Adversarial Search - which is used for problems like Tic-Tac-Toe games
So for games:
- S0 : initial state
- PLAYER(s) : returns which player to move in state s
- ACTIONS(s) : returns legal moves in state s
- RESULT(s, a) : returns state after action a taken in state s
- TERMINAL(s) : checks if state s is a terminal state
- UTILITY(s) : final numerical value for terminal state s
One method is called MinMax
- Given a state s:
- MAX picks action a in ACTIONS(s) that produces highest value of MIN-VALUE(RESULT(s, a))
- MIN picks action a in ACTIONS(s) that produces smallest value of MAX-VALUE(RESULT(s, a))
Or in code as:
function MAX-VALUE(state):
if TERMINAL(state):
return UTILITY(state)
v = -∞
for action in ACTIONS(state):
v = MAX(v, MIN-VALUE(RESULT(state, action)))
return v
function MIN-VALUE(state):
if TERMINAL(state):
return UTILITY(state)
v = ∞
for action in ACTIONS(state):
v = MIN(v, MAX-VALUE(RESULT(state, action)))
return v
And some special pruning method such as Alpha-Beta Pruning is needed for game problems with very large search space.
Divide and Conquer
- Divide into smaller problems
- Conquer via recursive calls
- Combine solutions of sub-problems into one for the original problem.
Typical problems:
-
Merge sort (recursive or bottom up)
-
Karatsuba Multiplication
-
Counting Inversions
Example: (1, 3, 5, 2, 4, 6), having inversions: (3,2), (5,2), (5, 4)
Can be used for: calculate the similarity between 2 persons' 10 movies sort order.
Counting Inversions
Naive implementation is \( O(n^2) \) as we need 2 for loops. Via divide and conquer, what we need is this
Count(array a, length n) {
if n == 1 return 0
else
x = Count(left half of a, n/2)
y = Count(right half of a, n/2)
z = CountSplitInv(a, n)
return x + y + z
}
CountSplitInv counting the split inversions, where first
index is in the first half array, and second index is in the
second half array.
Then the question is, can we do CountSplitInv with
\( O(n) \)? If so, the divide part has \( O(\log n) \), which gives us the final algorithms speed of \( O(n \log n) \). Intuitively feels not possible.
Piggybacking on Merge Sort
SortAndCount(array a, length n) {
if n == 1 return 0
else
b, x = SortAndCount(left half of a, n/2)
c, y = SortAndCount(right half of a, n/2)
d, z = MergeAndCountSplitInv(b, c, n)
return d, x + y + z
}
After sorting, we can do the trick, or "piggybacking" while merge:
i=0
j=0
z=0
for k = 0 .. n-1 {
if b[i] <= c[j] {
d[k] = b[i]
i++
} else {
d[k] = c[j]
j++
z += b.len - i // piggybacking part of merge
}
}
So if b's element all less than c's element,
before j starts to add, i will be as b.len, making z=0 in the end.
Or the general claim:
Claim: the numberr of split inversions involving an element
c_jfrom 2nd arraycis precisely the number of elements left in the 1st arraybwhenc_jis copied to the outputd.
So basically we ended with a very similar thing to Merge Sort, only one more operation on the merge operations. So we achieved \( O(n \log n) \). Pretty impressive.
The Master Method
\[ \begin{align} \text{If } \quad T(n) & <= a T (\frac{n}{b}) + O(n^d) \\ \text{Then } \quad T(n) & = \begin{cases} O(n^d \log n) & \quad \text{if } a = b^d \text{ (Case 1)} \\ O(n^d) & \quad \text{if } a < b^d \text{ (Case 2)} \\ O(n^{\log_{b}{a} }) & \quad \text{if } a > b^d \text{ (Case 3)} \end{cases} \end{align} \]
For example
- merge sort having
a=2, b=2, d=1so it is \( O(n \log n) \), which is case 1 - binary search having
a=1, b=2, d=0so it is \( O(\log n) \), which is case 1 - Karatsuba Multiplication
a=3, b=2, d=1so it is \( O(n^{\log_2 3}) = O(n^{1.59}) \), which is case 3
A simple proof could be: At each level \( j=0,1,2,..,log_b(n) \), there are \(a^j\) subproblems, each of size \( n \over b^j \). Then the total number of operations needed to solve the whole problem for each level is: \[ a^j C {\left[\frac{n}{b^j}\right]}^d = C n^d {\left[\frac{a}{b^d}\right]}^j \] Thus the total number of the whole problem is: \[ \text{total work} \leq \displaystyle\sum_{j=0}^{\log_b n} C n^d {\left[\frac{a}{b^d}\right]}^j \] where
- \( a \): rate of subproblem proliferation (
RSP) - \( b^d \): rate of work shrinkage per subproblem (
RWS)
And we see:
- If
RSP < RWS, then the amount of work is decreasing with the recursion levelj - If
RSP > RWS, then the amount of work is increasing with the recursion levelj - If
RSP = RWS, then the amount of work is the same at every recursion levelj
Sort
Merge sort
- \( n \log(n) \) in worst case
- a
stablesort (sort by column A, then sort by column B, then for the same B, order of A preserves) - simple to understand, divide and conquer (or bottom up to avoid recursion);
log(n)levels, and each level's merge takesnoperation, thus \( n \log(n) \) will do
Quick sort
- \( n \log(n) \) in worst case
- not a
stablesort - more tricky but not difficult to understand, divide and conquer:
make sure an element's left are all smaller (or equal to) it, and the right part are all bigger than it (let's called itpartitioned); then continue to sort both on left and right part;
Quick sort partition
To make an array partitioned by, for eg. the first element:
[3, 5, 2, 6, 1, 4]
i---^
j---^
Start with i and j both after first element.
i stands for left of me is smaller than pivot; j stands for left of me is partitioned.
So basically we loop each element until j is n;
For each step:
- If
a[j] >= pivot, then justj++; - If
a[j] < pivot, thenswap(i, j),i++, j++; - When
jreaches the end,swap(i-1, 0), returni-1
[3, 5, 2, 6, 1, 4]
i---^
j------^
swap
[3, 2, 5, 6, 1, 4]
i------^
j---------^
[3, 2, 5, 6, 1, 4]
i------^
j------------^
swap
[3, 2, 1, 6, 5, 4]
i---------^
j------------^
[3, 2, 1, 6, 5, 4]
i---------^
j-----------------^
then last swap and return i=2
[1, 2, 3, 6, 5, 4]
i---------^
j-----------------^
Quick sort pivot choose
If an input array is already sorted, simply choose pivod as the first element of the array will result the running time of quick sort to be \( n^2 \). That is not quick.
So if some "maigc" method out there can always choose the midiean value as the pivot, then the quick sort running back falls back to \( n \log(n) \).
A common way is to choose a random element as pivot. So with Random Pivot implemented, it can be approved that the total number of comparisons of quik-sort algorithms is equal or less than \( 2 n \ln(n) \), appriximately.
So quick sort will have more comparisions than merge sort, but as it needs no extra memory, so it is generally faster than merge sort.
Quick sort partition can be tricky
Many textbook implementations go quadratic if array
- Is sorted or reverse sorted
- Has many duplicates (even if randomized) (the standford course impl perhaps?)
Quick sort practical improvements
- Median of sample
- Best choice of pivot item = median
- Estimate true median by taking median of sample
- Median-of-3 (random) items (which is also used in Rust's quicksort code)
Quick select
The expected running time to find the median (or the kth largest value) of an array of nn distinct keys using randomized quickselect is linear.
Duplicated keys - 3-way partition
Simply put all equal values together
- 3-way partitioning: Goal - partition array into 3 parts
- lo, lt, gt, hi
- start with
lt=lo+1, gt=lo+1 - end with
higoes out length range
For each step:
- If
a[hi] > pivot, then justhi++; - If
a[hi] == pivot, thenswap(gt, hi),gt++, hi++ - If
a[hi] < pivot, thenswap(gt, hi),swap(lt, gt),lt++, gt++, hi++; - When
hireaches the end,swap(lt-1, 0), returnlt-1, gt
[3, 2, 1, 3, 3, 5, 6, 3, 1]
lt--------^
gt--------------^
hi-----------------^
[3, 2, 1, 3, 3, 5, 6, 3, 1]
lt--------^
gt--------------^
hi--------------------^
[3, 2, 1, 3, 3, 3, 6, 5, 1]
lt--------^
gt-----------------^
hi--------------------^
[3, 2, 1, 3, 3, 3, 6, 5, 1]
lt--------^
gt-----------------^
hi-----------------------^
swap(gt, hi)
[3, 2, 1, 3, 3, 3, 1, 5, 6]
lt--------^
gt-----------------^
hi-----------------------^
swap(lt, gt)
[3, 2, 1, 1, 3, 3, 3, 5, 6]
lt--------^
gt-----------------^
hi-----------------------^
lt++, gt++, hi++
[3, 2, 1, 1, 3, 3, 3, 5, 6]
lt-----------^
gt--------------------^
hi--------------------------^
Or a "from two end" approach could be like this:

Bottom line
Randomized quicksort with 3-way partitioning reduced running time from linearithmic to liner in broad class of applications.
Java Implementation
Arrays.sort() in Java use mergesort instead of quicksort when sorting reference types, as it is stable and guarantees \( n \log(n) \) performance
Tukey's ninther
Median of the median of 3 samples. Approximates the median of 9 evenly spaced entries. Uses at most 12 compares.
Seems used in Rust's quicksort as well.
Summary

Priority Queue - Binary Heap and Heap Sort
Priority Queue is super useful for fast Breadth-First Search (BFS) in algorithms like A* search, or it can be used in sort algorithm called Heap Sort (basically you make a Priority queue then pop out elements and they will be in order)
It needs to implement two operations efficiently:
- remove the maximum
- insert
Priority queue applications
- Event-driven simulation. [customers in a line, colliding particles]
- Numerical computation. [reducing roundoff error]
- Data compression. [Huffman codes]
- Graph searching. [Dijkstra's algorithm, Prim's algorithm]
- Number theory. [sum of powers]
- Artificial intelligence. [A* search]
- Statistics. [maintain largest M values in a sequence]
- Operating systems. [load balancing, interrupt handling]
- Discrete optimization. [bin packing, scheduling]
- Spam filtering. [Bayesian spam filter]


Priority Queue can be implemented via binary heap - which is an array representation of a heap-ordered complete binary tree.

- Largest key is
a[1], which is root of binary tree. - Can use array indices to move through tree.
- Parent of node at
kis atk/2. - Children of node at
kare at2kand2k+1.
- Parent of node at
Binary Heap
The binary heap is a data structure that can efficiently support the basic priority-queue operations. A binary tree is heap-ordered if the key in each node is larger than or equal to the keys in that node's two children (if any).
- Height of complete tree with N nodes is
lg N - Array representation, with indices start at 1, largest key at the root
- Take nodes in level order
- No explicit links needed!
- Largest key is a[1], which is root of binary tree
- Can use array indices to move through tree
- Parent of node at k is at
k/2 - Children of node at k are at
2kand2k+1
- Parent of node at k is at





Here is the code summary:
public class MaxPQ<Key extends Comparable<Key>>
{
private Key[] pq;
private int N;
public MaxPQ(int capacity)
{ pq = (Key[]) new Comparable[capacity+1]; }
public boolean isEmpty()
{ return N == 0; }
private boolean less(int i, int j)
{ return pq[i].compareTo(pq[j]) < 0; }
private void exch(int i, int j)
{ Key t = pq[i]; pq[i] = pq[j]; pq[j] = t; }
// promotion
private void swim(int k)
{
while (k > 1 && less(k/2, k)) {
exch(k, k/2);
k = k/2;
}
}
// insert
public void insert(Key x) {
pq[++N] = x;
swim(N);
}
// demotion
private void sink(int k) {
while (2*k <= N) {
int j = 2*k;
if (j < N && less(j, j+1)) j++;
if (!less(k, j)) break;
exch(k, j);
k = j;
}
}
// delete max
public Key delMax() {
Key max = pq[1];
exch(1, N--);
sink(1);
pq[N+1] = null; // prevent loitering
return max;
}
}



One more note: Use immutable keys if you can!
Heapsort

public static void sort(Comparable[] a) {
int N = a.length;
// first pass - heap construction
for (int k = N/2; k >= 1; k--)
sink(a, k, N);
// second pass - remove max one at a time
while (N > 1) {
exch(a, 1, N);
sink(a, 1, --N);
}
}
- Heap construction is in linear time, uses ≤ 2 N compares and exchanges
- No extra memory needed, ≤ 2 N log N compares and exchanges !!!
Heapsort significane In-place sorting algorithm
- Mergesort: need extra space, (otherwise there is a not practical way)
- Quicksort: quadratic time in worst case (N ln N via probabilistic guarantee, fast in practise)
- Heapsort: Yes ! 2 N log N worst case
Bottom line. Heapsort is optimal for both time and space, but:
- Inner loop longer than quicksort’s. (each time sink needs to compare with 2 children)
- Makes poor use of cache memory. (memory ref jumps around too much)
- Not stable.
Dynamic programming
Fibonacci
Recursion - Exponential waste
A novice programmer might implement a recersion like this below. But it has a problem called expoential waste.
public class FibonacciR
{
public static long F(int n)
{
if (n == 0) return 0;
if (n == 1) return 1;
return F(n-1) + F(n-2);
}
public static void main(String[] args)
{
int n = Integer.parseInt(args[0]);
StdOut.println(F(n));
}
}
The issue of the recursion above is that there are many duplicated calculations performed. So the core of the algorithms of opertimization is to reduced the number of operations. And since we have many calculation already done so there should be a way to save the results, then later calculations can use the previous calculatined values.
This could be the core idea of Dynamic programming.
Avoiding exponential waste
Memoization
- Maintain an array
memo[]to remember all computed values. - If value known, just return it.
- Otherwise, compute it, remember it, and then return it.
public class FibonacciM
{
static long[] memo = new long[100];
public static long F(int n)
{
if (n == 0) return 0;
if (n == 1) return 1;
if (memo[n] == 0)
memo[n] = F(n-1) + F(n-2);
return memo[n];
}
public static void main(String[] args)
{
int n = Integer.parseInt(args[0]);
StdOut.println(F(n));
}
}
Dynamic programming
Dynamic programming.
- Build computation from the "bottom up".
- Solve small subproblems and save solutions.
- Use those solutions to build bigger solutions.
public class Fibonacci
{
public static void main(String[] args)
{
int n = Integer.parseInt(args[0]);
long[] F = new long[n+1];
F[0] = 0; F[1] = 1;
for (int i = 2; i <= n; i++)
F[i] = F[i-1] + F[i-2];
StdOut.println(F[n]);
}
}
DP example: Longest common subsequence (LCS)



LCS length implementation
public class LCS
{
public static void main(String[] args)
{
String s = args[0];
String t = args[1];
int M = s.length();
int N = t.length();
int[][] opt = new int[M+1][N+1];
for (int i = M-1; i >= 0; i--)
for (int j = N-1; j >= 0; j--)
if (s.charAt(i) == t.charAt(j))
opt[i][j] = opt[i+1][j+1] + 1;
else
opt[i][j] = Math.max(opt[i+1][j], opt[i][j+1]);
System.out.println(opt[0][0]);
}
}

More notes will come when the alg course touches on dynamic programming later. The above content are from the Princeton's course Computer Science: Programming with a Purpose.
A * Search homework
Write a program to solve the 8-puzzle problem (and its natural generalizations) using the A* search algorithm.

The problem
The 8-puzzle is a sliding puzzle that is played on a 3-by-3 grid with 8 square tiles labeled 1 through 8, plus a blank square. The goal is to rearrange the tiles so that they are in row-major order, using as few moves as possible. You are permitted to slide tiles either horizontally or vertically into the blank square. The following diagram shows a sequence of moves from an initial board (left) to the goal board (right).

Board data type
To begin, create a data type that models an n-by-n board with sliding tiles. Implement an immutable data type Board with the following API:
public class Board {
// create a board from an n-by-n array of tiles,
// where tiles[row][col] = tile at (row, col)
public Board(int[][] tiles)
// string representation of this board
public String toString()
// board dimension n
public int dimension()
// number of tiles out of place
public int hamming()
// sum of Manhattan distances between tiles and goal
public int manhattan()
// is this board the goal board?
public boolean isGoal()
// does this board equal y?
public boolean equals(Object y)
// all neighboring boards
public Iterable<Board> neighbors()
// a board that is obtained by exchanging any pair of tiles
public Board twin()
// unit testing (not graded)
public static void main(String[] args)
}
Constructor. You may assume that the constructor receives an n-by-n array containing the \( n^2 \) integers between 0 and \(n^2 − 1\), where 0 represents the blank square. You may also assume that 2 ≤ n < 128.
String representation. The toString() method returns a string composed of n + 1 lines. The first line contains the board size n; the remaining n lines contains the n-by-n grid of tiles in row-major order, using 0 to designate the blank square.

Hamming and Manhattan distances. To measure how close a board is to the goal board, we define two notions of distance.
The Hamming distance betweeen a board and the goal board is the number of tiles in the wrong position.
The Manhattan distance between a board and the goal board is the sum of the Manhattan distances (sum of the vertical and horizontal distance) from the tiles to their goal positions.

Comparing two boards for equality. Two boards are equal if they are have the same size and their corresponding tiles are in the same positions.
The equals() method is inherited from java.lang.Object, so it must obey all of Java’s requirements.
Neighboring boards. The neighbors() method returns an iterable containing the neighbors of the board. Depending on the location of the blank square, a board can have 2, 3, or 4 neighbors.

Unit testing. Your main() method should call each public method directly and help verify that they works as prescribed (e.g., by printing results to standard output).
Performance requirements. Your implementation should support all Board methods in time proportional to n2 (or better) in the worst case.
A* search. Now, we describe a solution to the 8-puzzle problem that illustrates a general artificial intelligence methodology known as the A* search algorithm.
We define a search node(or called as state in other context) of the game to be a board, the number of moves made to reach the board, and the previous search node. First, insert the initial search node (the initial board, 0 moves, and a null previous search node) into a priority queue. Then, delete from the priority queue the search node with the minimum priority, and insert onto the priority queue all neighboring search nodes (those that can be reached in one move from the dequeued search node). Repeat this procedure until the search node dequeued corresponds to the goal board.
The efficacy of this approach hinges on the choice of priority function for a search node. We consider two priority functions:
- The Hamming priority function is the Hamming distance of a board plus the number of moves made so far to get to the search node. Intuitively, a search node with a small number of tiles in the wrong position is close to the goal, and we prefer a search node if has been reached using a small number of moves.
- The Manhattan priority function is the Manhattan distance of a board plus the number of moves made so far to get to the search node.
To solve the puzzle from a given search node on the priority queue, the total number of moves we need to make (including those already made) is at least its priority, using either the Hamming or Manhattan priority function. Why? Consequently, when the goal board is dequeued, we have discovered not only a sequence of moves from the initial board to the goal board, but one that makes the fewest moves. (Challenge for the mathematically inclined: prove this fact.)
Game tree. One way to view the computation is as a game tree, where each search node is a node in the game tree and the children of a node correspond to its neighboring search nodes. The root of the game tree is the initial search node; the internal nodes have already been processed; the leaf nodes are maintained in a priority queue; at each step, the A* algorithm removes the node with the smallest priority from the priority queue and processes it (by adding its children to both the game tree and the priority queue).
For example, the following diagram illustrates the game tree after each of the first three steps of running the A* search algorithm on a 3-by-3 puzzle using the Manhattan priority function.

Solver data type. In this part, you will implement A* search to solve n-by-n slider puzzles. Create an immutable data type Solver with the following API:
public class Solver {
// find a solution to the initial board (using the A* algorithm)
public Solver(Board initial)
// is the initial board solvable? (see below)
public boolean isSolvable()
// min number of moves to solve initial board; -1 if unsolvable
public int moves()
// sequence of boards in a shortest solution; null if unsolvable
public Iterable<Board> solution()
// test client (see below)
public static void main(String[] args)
}
Implementation requirement. To implement the A* algorithm, you must use the MinPQ data type for the priority queue.
Corner cases.
- Throw an IllegalArgumentException in the constructor if the argument is null.
- Return -1 in moves() if the board is unsolvable.
- Return null in solution() if the board is unsolvable.
Test client. The following test client takes the name of an input file as a command-line argument and prints the minimum number of moves to solve the puzzle and a corresponding solution.
public static void main(String[] args) {
// create initial board from file
In in = new In(args[0]);
int n = in.readInt();
int[][] tiles = new int[n][n];
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
tiles[i][j] = in.readInt();
Board initial = new Board(tiles);
// solve the puzzle
Solver solver = new Solver(initial);
// print solution to standard output
if (!solver.isSolvable())
StdOut.println("No solution possible");
else {
StdOut.println("Minimum number of moves = " + solver.moves());
for (Board board : solver.solution())
StdOut.println(board);
}
}
The input file contains the board size n, followed by the n-by-n grid of tiles, using 0 to designate the blank square.

Two optimizations. To speed up your solver, implement the following two optimizations:
- The critical optimization. A* search has one annoying feature: search nodes corresponding to the same board are enqueued on the priority queue many times (e.g., the bottom-left search node in the game-tree diagram above). To reduce unnecessary exploration of useless search nodes, when considering the neighbors of a search node, don’t enqueue a neighbor if its board is the same as the board of the previous search node in the game tree.

- Caching the Hamming and Manhattan priorities. To avoid recomputing the Manhattan priority of a search node from scratch each time during various priority queue operations, pre-compute its value when you construct the search node; save it in an instance variable; and return the saved value as needed. This caching technique is broadly applicable: consider using it in any situation where you are recomputing the same quantity many times and for which computing that quantity is a bottleneck operation.
Detecting unsolvable boards. Not all initial boards can lead to the goal board by a sequence of moves, including these two:

To detect such situations, use the fact that boards are divided into two equivalence classes with respect to reachability:
- Those that can lead to the goal board
- Those that can lead to the goal board if we modify the initial board by swapping any pair of tiles (the blank square is not a tile)
(Difficult challenge for the mathematically inclined: prove this fact.) To apply the fact, run the A* algorithm on two puzzle instances—one with the initial board and one with the initial board modified by swapping a pair of tiles—in lockstep (alternating back and forth between exploring search nodes in each of the two game trees). Exactly one of the two will lead to the goal board.
Summary
I have some sample solution here for this exercises.
The most important hints could be:
- You would need to implement a linked list type of structure to keep all the visited states and link them to the current state so to allow it to be traced back in the end.
- For that critical optimizaiton part where making sure we don't insert a visitedstate into the frontier again. I initially tried to put all the visited state in a large SET and each time check the common set whether it contains the state before inserting but that apparently is not always correct (and it is slow). One only need to check all the state in it's state chain to know whether it is a state can be inserted to frontier. Also as we are not dealing some type of circled graphs so to speed up we only needed to check the state (one of the neighbor) a single time with current state's previous state.
Binary search tree (BST)
Key-value pair abstraction - Map/Dictionary
- key -> value
- insert
- search/get
- delete
Binary search tree (BST)
- Each node has a key
- For every key:
- Larger than all keys in its left subtree
- Smaller than all keys in its right subtree













So with BST the drawback includes:
- No good guarantee that if insertion has order, the tree will be imbalanced. (The red black tree can help)
- when deleting: the order of growth of the expected height of a binary search tree with n keys after a long intermixed sequence of random insertions and random Hibbard deletions is:
sqrt(N). This currently is not optimized tolog Nand it is an open question.
Notes on delete






Balanced Search Trees
Binary Heapor priority queue is good formax()ormin()as it is only O(1), however it only supportdelMax/Min()and not good for search.Binary search treeis good for search, rank, insert and delete, also quite good for finding max and min, all these operation is O(log N), if the tree can be balanced.Hash Tableis super good for search/look-up (O(1)), insert and delete, but not good for operations such as rank, min, or max.
Red-Black BSTs
Link to course presentations.
BTS - binary search tree is a very good data structure
that has fast insert and search property. One key point
in making a BST to work well for any cases is to keep
the tree balanced, or to keep the height of tree as
low as possible. This is achieved via algorithms such
as 2-3 tree and Red-Black tree (which is a different
representation of 2-3 tree).
2-3 tree
Allow 1 or 2 keys per node.
- 2-node: one key, two children.
- 3-node: two keys, three children.
- 4-node: a special temporary condition, 4 children, only exist for a short time while inserting
Guaranteed logarithmic performance for search and insert, worst case: \(height \leq c log_{2}(n) \)
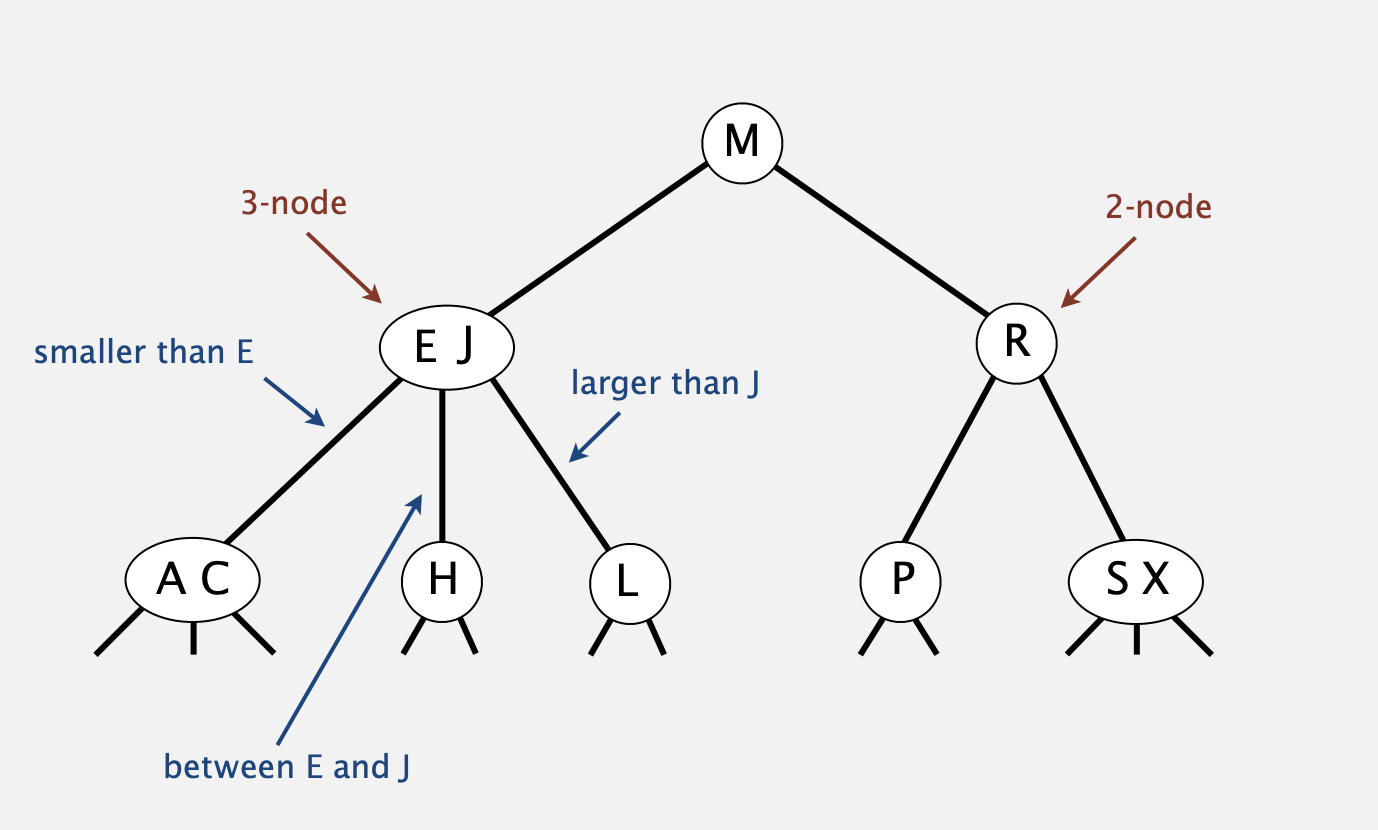
Insertion into a 3-node at bottom.
- Add new key to 3-node to create temporary 4-node.
- Move middle key in 4-node into parent.
- Repeat up the tree, as necessary.
- If you reach the root and it's a 4-node, split it into three 2-nodes.
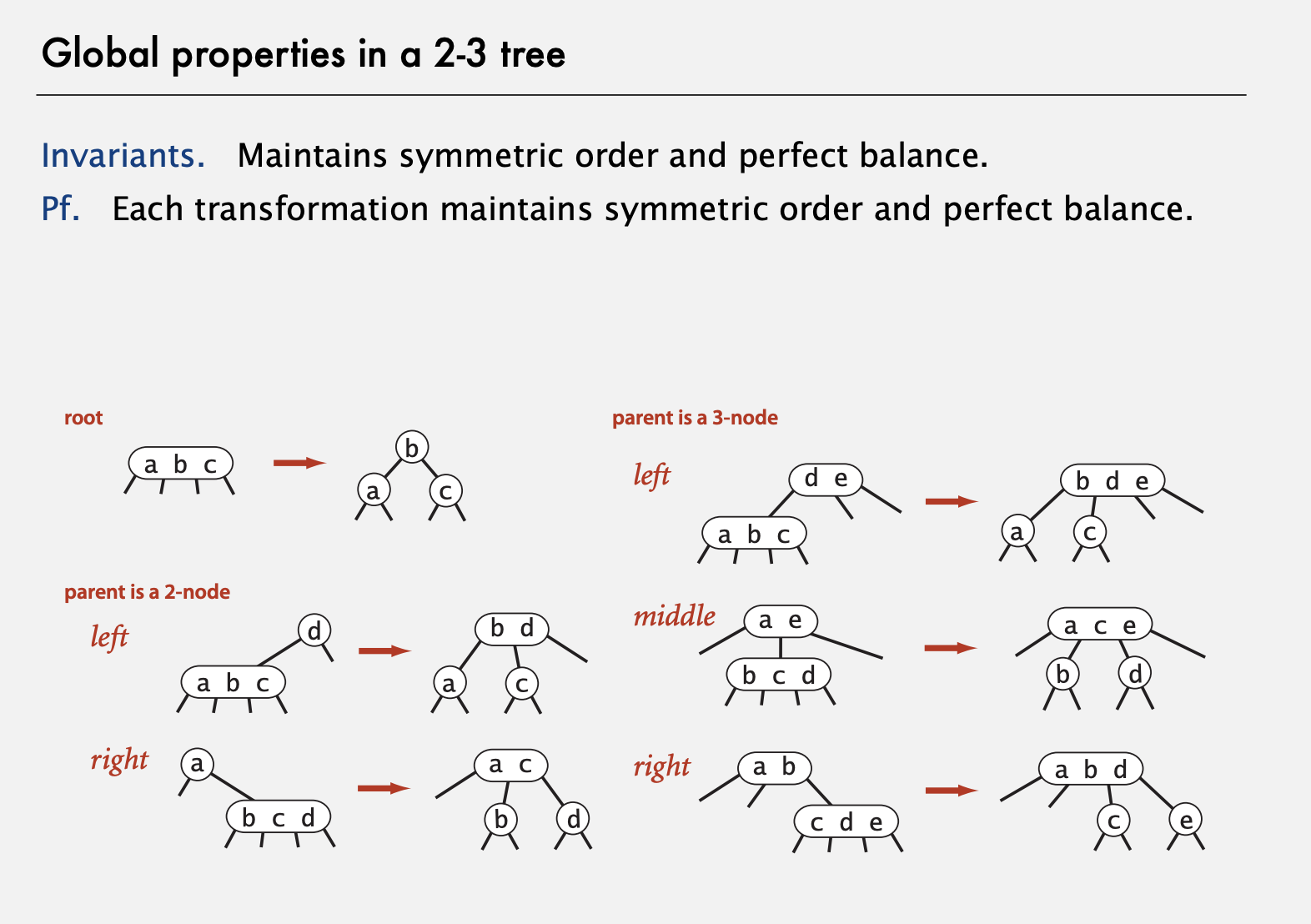
Left-leaning red-black BSTs (Guibas-Sedgewick 1979 and Sedgewick 2007)
Idea: ensure that hight always O(log N) (best possible)
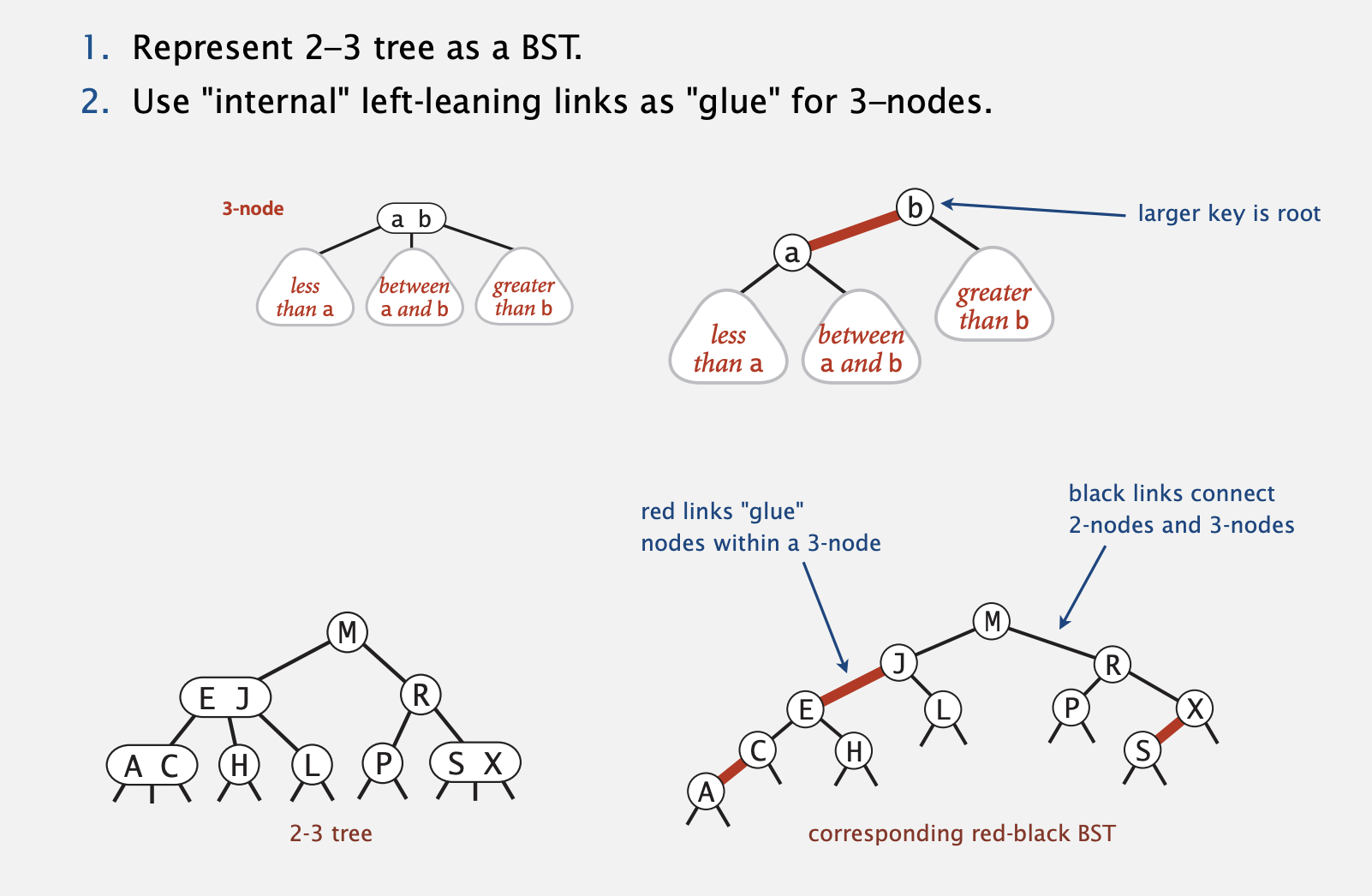
A Red-Black BST that has rules:
- each node
redorblack - root is always black
- no red nodes in a row
- red node => only black children
- every root-Null path (like in an unsuccessful search) has the same number of black nodes
- red links lean left
Left-leaning red-black BSTs: 1-1 correspondence with 2-3 trees
Hight Guarantee: if it is a red-black tree with n nodes, then it has \(height \leq 2 log_{2}(n + 1) \)
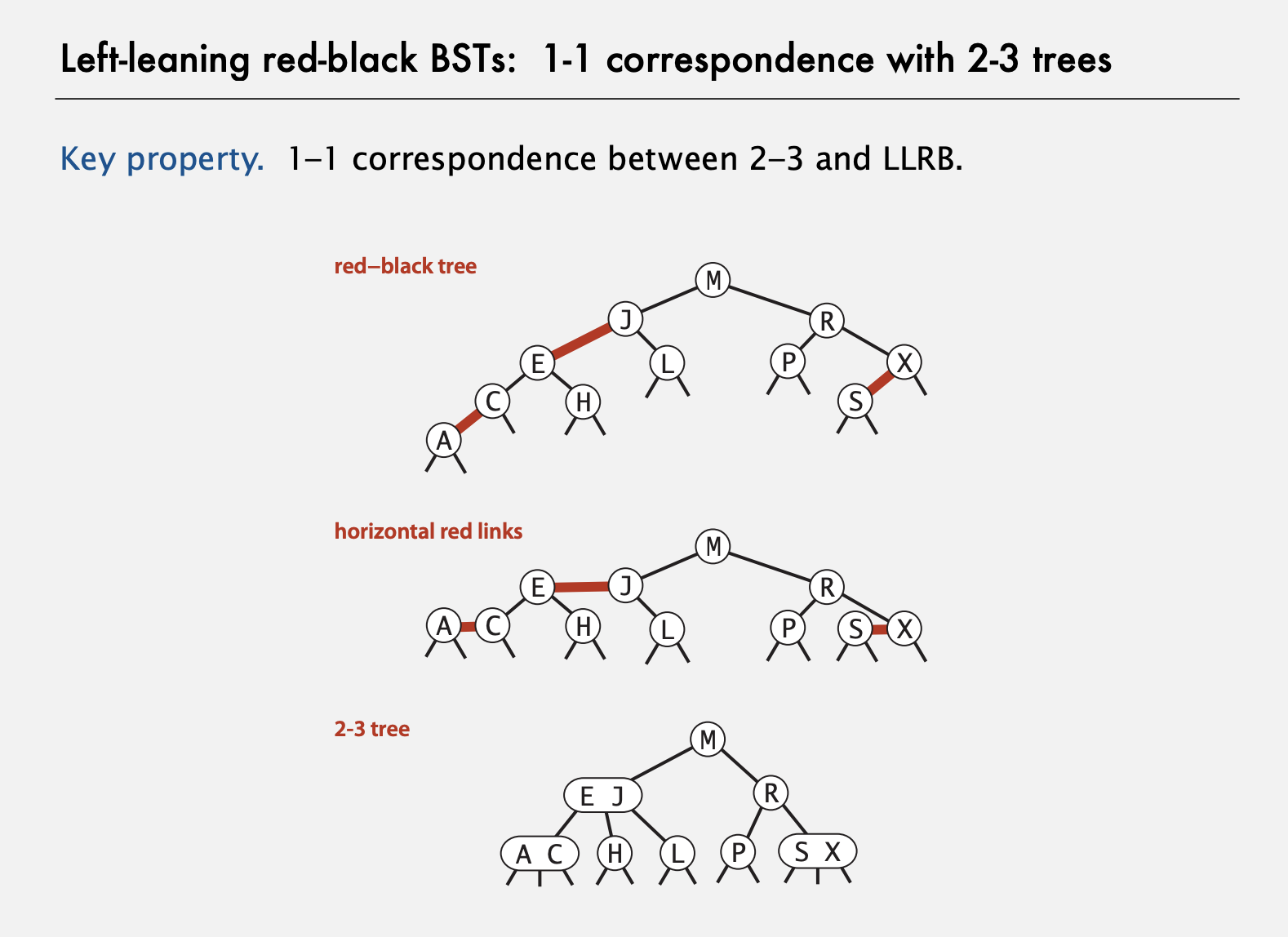
Every root to leaf path has the same number of black nodes
Sedgewick's friend wrote him a late night email telling him in this show they actually got the line for Red-Black tree correct. (And I don't think that helps with the ladies :) )
Click to see scripts...

Achieved by 3 basic operations
- Left Rotation
- Right Rotation
- Flip Colors

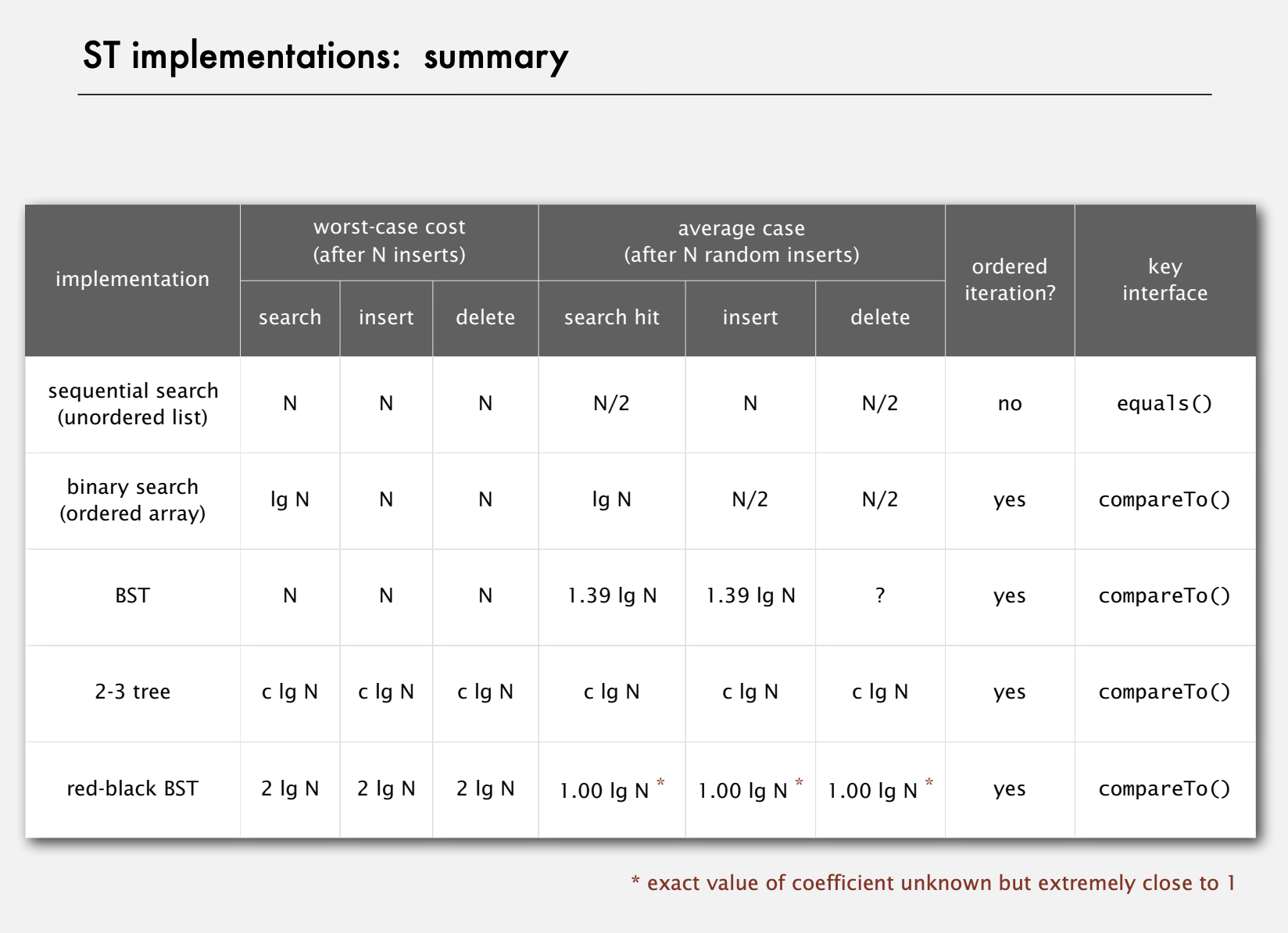
B-Trees






Kd-Trees
Geometric application of BSTs
1d range search
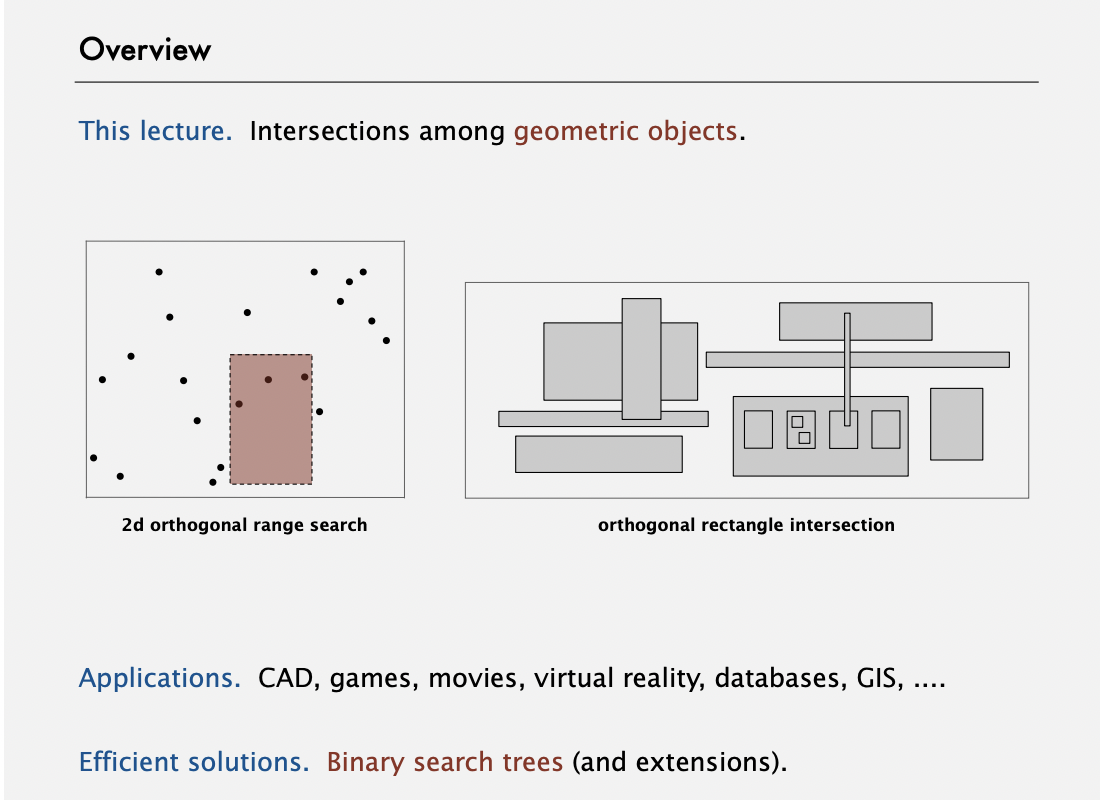

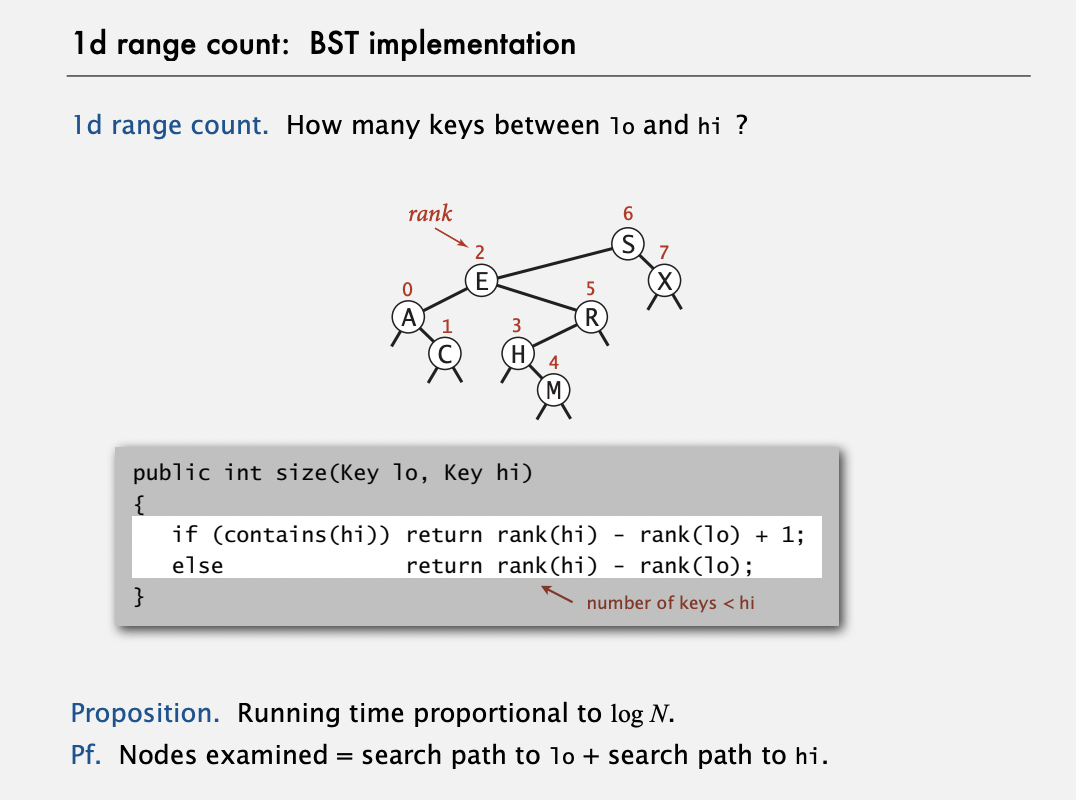
1d range counton BST can be achieved with recursiverank()calls.

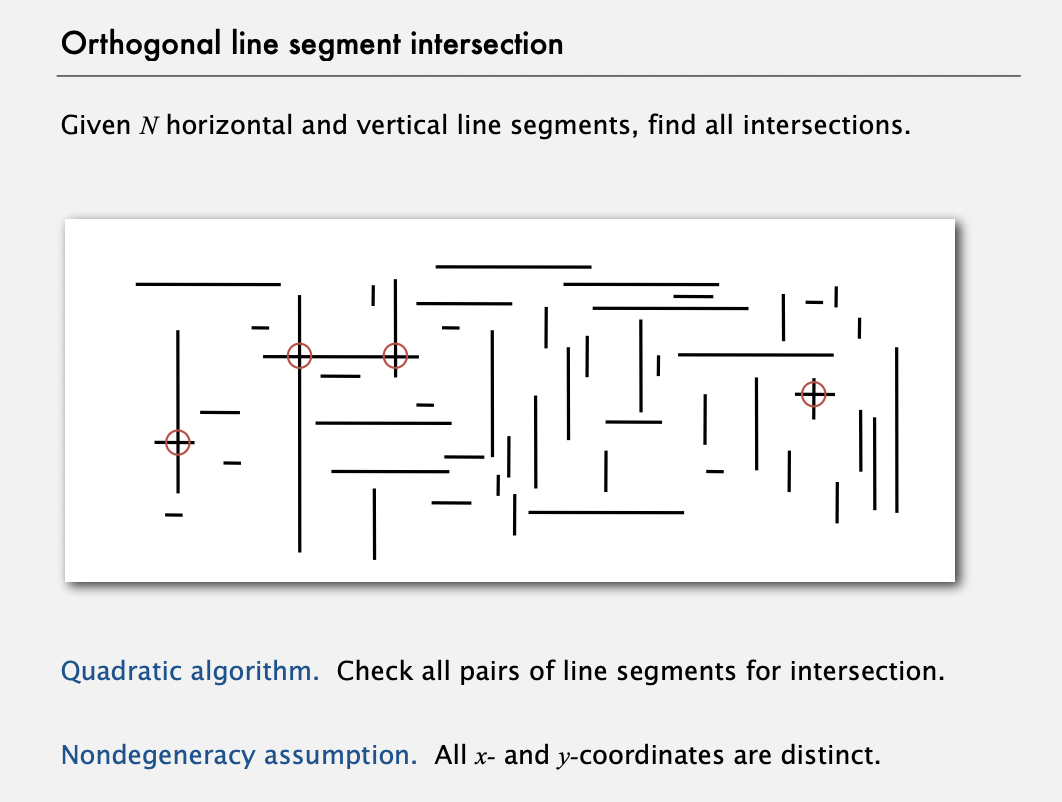
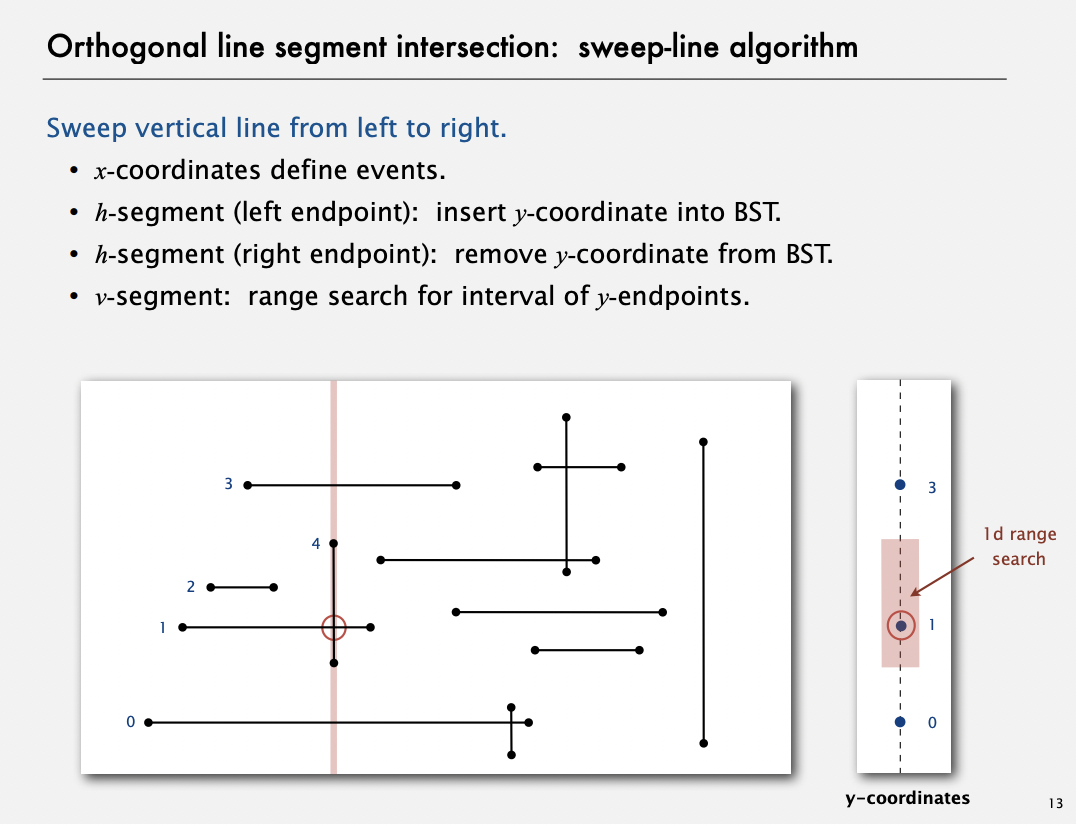
Orthogonal line segment intersection - sweep line algorithm

2-d orthogonal range search - Kd-trees
Kd tree: Recursively partition k-dimensional space into 2 halfspaces
Raft - learning from MIT 6.824
- Course info at https://pdos.csail.mit.edu/6.824/labs/lab-raft.html
- Paper at https://raft.github.io/raft.pdf
- A very good YouTube video


Raft Core Feature
If committed --meaning--> Present in the future leader's logs, and this is achieved by:
- Restrictions on leader election (See voting rules)
- Restrictions on commit
Leader Election
We firstly look at Leader Election mechanism - which is implemented by two parts:
RequestVote- each node start asFollowerand whenelection timeoutpasses and no HeartBeat received before, then a node step up asCandidateand send votes to rest of the nodes and if collect more than half (count itself as well), it steps up as aLeader, which keeps sendingHeartBeatto others.HeartBeat - a.k.a Empty AppendEntries RPC

Besides, the tips on the paper and the lab2a websites, I encountered a few other pitfalls (which might be mentioned somewhere in to docs)
Candidates
- In order to make the tests can pass with limited running time, I have to make sure when a candidate sends vote requests out and wait, it should stop waiting as long as it already got enough majority votes.
- The same applies when a leader is waiting for heatbeats. Don't wait after quorum votes have been fetched.
- Each places when a candidate/leader step down to a follower,
remember to set
votedForback tonilor-1so to allow it gives a valid vote in the next round of voting process. - Not like Follower, Candidates can probably send out the next round of vote
with a shorter and fixed Duration than
a Follower's
election timeout duration, in the case when this round of vote does not get enough votes; But at the same time
Getting vote request as Candidate
- It seems not necessary, but I also added the logic (seem to be safer): If myself is a Candidate and the other node (candidate) want me to vote to her, if we have the same term value, then I don't vote to her (so as she won't vote for me neither);
Standard Voting Rules when got Voting Request:
- If request term lass than my term, ignore. Reply my term.
- So when request term >= my term,
- From
Rules for Servers: If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower - The candidate situation mentioned above
- if
notYetVotedorvotedTheSameBefore, then do the vote, setvotedForand reset myelection timeout; It is important to havevotedForset and checked here as it helps in the case where there is multiple candidates alive, then no multiple leaders are selected, as we make sure each voter can only vote to one candidate.
- From
- Restrictions on leader election
- When voting, include
lastLogIndexandlastLogTerm - Voting server
vdenies vote if its log is "more complete":if (lastTerm_v > lastTerm_c) || (lastTerm_v == lastTerm_c) && (lastIndex_v > lastIndex_c) return false
- When voting, include
HeartBeat - a.k.a Empty AppendEntries RPC
After the Leader is elected, the electionTimeoutTime or election timeout should then be
constantly refreshed with each HeartBeat - which is achieved by sending empty
AppendEntries RPC calls.
The basic rules are like:
- From
Rules for Servers: If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower
The code could be something like this
func (rf *Raft) HeartBeat(args *HeartBeatRequest, reply *HeartBeatReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if args.Term >= rf.term {
rf.state = Follower // step down
rf.votedFor = args.From
rf.term = args.Term
rf.electionTimeoutTime = time.Now().Add(rf.getElectionTimeoutDuration())
reply.Good = true
reply.Term = rf.term
return
} else {
reply.Good = false
reply.Term = rf.term
return
}
}
AppendEntries RPC

Tricky part summary
Leader ticker and Candidate ticker
The candidate ticker can be done with just a single thread loop
and it is okay to set up a timeout as well. For the critical
conditions of TestFigure8Unreliable2C, it will mostly work
well as long as we make sure timeout is relatively large so
we can always have a candidate selected after a few rounds.
But for the leader ticker we cannot use single thread call with a long timeout anymore as if we do that, the timeout will be a time much longer than the election timeout of other followers then it ended up constantly new candidate showing up.
However, if we let leader ticker async, for example, start a goroutine and send a HeartBeat call every 100ms, then the other subtle issue is that we have to make sure, when those goroutines finishes in different time and order, we can still handle things correctly.
A few places to worth notice and mention:
- For each leader ticker goroutine, after getting reply from any followers, do a check of the leader's states and term as the leader might have already been converted to a follower by other leader
- when leader to update
nextIndexfor a follower, check it can only be larger thanmatchedIndexin case the HeartBeats to the same follower replied out of order.
Follower Log correction Speed-Up This is where the paper didn't say much, but basically there is two cases we need to speed-up follower log.
- During follower replying
HeartBeat, when follower'sLastLogTermis greater than leader'srf.log[nextIndex-1].Term(orargs.PrevLogTerm), so we rollnextIndexto the smaller side until it reaches an entry with the same term as leader'sPrevLogTerm, by cutting follower's log and replying to leader with a smallerLastLogIndex;
Also, when PrevLogIndex/Term matches, remove all the following entries that starts with a miss match of any entry term from leader's incoming entriesLeader: [0, 1, 1, 2, 2, 2, 4, 4,] Entries: ^ [2, 4, 4,] Follower: [0, 1, 1, 3, 3, ] then we should cut it to: [0, 1, 1, ] <-----------------------| ^-------new `nextIndex` found by `LastLogIndex`Leader: [0, 1, 1, 2, 2, 2, 4, 4,] Entries: ^ [2, 4, 4,] Follower: [0, 1, 1, 2, 2, 2, 3, 3, 3, 3] then we should cut it to: [0, 1, 1, 2, 2, 2, 4, 4,] <-----------------------| - During leader's handling of a follower's reply of
HeartBeat, where the follower'sLastLogTermis less than leader'srf.log[nextIndex-1].Term, so we rollnextIndexto the smaller side until it reaches an entry with the same term as follower'sLastLogTerm.Leader: [0, 1, 2, 2, 2, 2, 4, 4,] Entries: ^ [2, 4, 4,] Follower: [0, 1, 1, 1, 1, 1, 1, 1, ] then we should cut it to: [0, 1, 1, 1, ] <-----------------------------| ^--------------- and also send back `LastLogTerm` as 1 so to let leader set `nextIndex` to the place just after the last entry of term = LastLogTerm ^----------------- new `nextIndex` found by `LastLogTerm`
Async commit and updating rf.commitIndex
The actual apply of those logs and update of rf.commitIndex
can be done async with a single goroutine.
Important fix for TestFigure8Unreliable2C's commits not sync issue here - as we added some optimization on
- Leader only sends part of new entries when there are more than a max number (500 in this case) of new entries that are not on the follower
- When a Follower is handling the heartbeat, it does not touch the log if the incoming entries have been existing/duplicated, leaving some entries after the incoming entry part untouched/uncut as well. However, the entries in the latter part might not be valid.
So with those optimizations mentioned above, at the place when we update the follower's rf.commitIndex, we cannot go as far as the leader's commitIndex, but only goes to the end index of the incoming replicating entry parts - which is args.PrevLogIndex+len(args.Entries)
Or see some comments on this Lab2C PR
Cache
- Single Node
- LRU - least recently updated cache
- a map for keep values for search and delete
- a double-linked list as queue to remove least recently updated value
- LRU - least recently updated cache
- Distributed
- shard
- so to save more data in total
- each shard is on its own server
- one shard could be hot, and data can loss if one shard dies - solved by replication
- replication
- how to
- leader, follwer
- put/get to leader
- get to follwers
- leader sends data to follwer
- leader election methods
- using configuration service
- leader election in a shard group
- ruft, strong consistency
- gossip, enventual consistency
- leader, follwer
- adding availability
- okay to miss some set in corner cases, cache speed/latency is more important
- scaling out can also help solving hot shard issue
- how to
- consistent hashing
- multiple positions positions on circle for each nodes
- shard
- CAP
- Consistency (not favourd)
- Get on a replica after a set could be missed when data is replicating from leader to replicas async
- Cache servers might go down and up
- Availabilty (favoured)
- Consistency (not favourd)
- Data expiration
- during client fetch or via client expire call
- active with a vacuum/gc thread
- when # of keys are too large, use some probabilistic way to random check each key instand loop the key range
- Cache client
- all clients know about all cache servers and
should have the same list of servers
- Maintaining a list of cache server,
how?
- Use configuration management tools (e.g. Puppet) to deploy modified file to every service host
- Use a S3 file to share a config file
- Configuration service (e.g.
ZooKeeper, Redis Sentinel) -
discover cache host, monitoring
their health
- Each cache server connect and send heart beats
- Costly on build and maintain, but fully automize the list info update
- Another benefit
- Maintaining a list of cache server,
how?
- client store list of servers in sorted order by hash value (e.g. TreeMap)
- Binary search is used to identify server (log n)
- Use TCP or UDP protocol to talk to servers
- If server unavailable, client proceeds as though it was a cache miss
- all clients know about all cache servers and
should have the same list of servers
- Detailed topics
- Monitoring and logging
- Network IO
- QPS
- Miss rate
- security - should only exposed internally
- Monitoring and logging
- Questions
- I wonder how do you sync data into a newly started replica in a shard group. Simply copy all data in the leader's memory to the new replica node? Wouldn't that consumes quite a lot of the leader's CPU?
Rust note
C++ memory mode
Memory order
- Acquire / Release
- Sequentially Consistent (SeqCst)
- Relaxed
Acquire-Release
Sort of like mutex primitives, aquire=lock, release=unlock. Acquire and Release are largely intended to be paired.
-
releaseupdate the memory, "publish" to other threads, used only withstoretype operation(save/publish data out, cannot use with load) -
acquirememory "published" by other threads, making it available to us, used only withloadtype of operation (cannot use with store) -
For "load and store" type of operation:
releasewill make loadrelaxedand storereleaseacquirewill make loadacquireand storerelaxed
-
AcqRelor acquire and release also exist, so can be used for "load and store" type of operation, making loadacquireand storerelease(no relaxed). This operation order could be handy for situation such as for an Arc type of thing in the end to drop the internal object, it may use some operation likeload_and_minors_1_then_storeso you would use thisAcqRelto make sure the thread got the updated value and all other threads has updated value when they read. This is illustrated in the video.
Intuitively, an acquire access ensures that every access after it stays after it. However operations that occur before an acquire are free to be reordered to occur after it. Similarly, a release access ensures that every access before it stays before it. However operations that occur after a release are free to be reordered to occur before it.
When thread A releases a location in memory and then thread B subsequently acquires the same location in memory, causality is established. Every write (including non-atomic and relaxed atomic writes) that happened before A's release will be observed by B after its acquisition. However no causality is established with any other threads. Similarly, no causality is established if A and B access different locations in memory.
Or using the words from the video:
- acquire/release: no total order of events
- each thread has it view of consistent ordering
Basic use of release-acquire is therefore simple: you acquire a location of memory to begin the critical section, and then release that location to end it. For instance, a simple spinlock might look like:
use std::sync::Arc; use std::sync::atomic::{AtomicBool, Ordering}; use std::thread; fn main() { let lock = Arc::new(AtomicBool::new(false)); // value answers "am I locked?" // ... distribute lock to threads somehow ... // Try to acquire the lock by setting it to true while lock.compare_and_swap(false, true, Ordering::Acquire) { // c++ code here could be: std::this_threadd::yield() to let other thread run } // broke out of the loop, so we successfully acquired the lock! // ... scary data accesses, but safe to do stuff here ... // ok we're done, release the lock lock.store(false, Ordering::Release); }
Sequentially Consistent
Be cause there is no total order of events for acquire/release, Sequentially Consistent is introduced.
Sequentially Consistent is the most powerful of all, implying the restrictions of all other orderings. Intuitively, a sequentially consistent operation cannot be reordered: all accesses on one thread that happen before and after a SeqCst access stay before and after it. A data-race-free program that uses only sequentially consistent atomics and data accesses has the very nice property that there is a single global execution of the program's instructions that all threads agree on. This execution is also particularly nice to reason about: it's just an interleaving of each thread's individual executions. This does not hold if you start using the weaker atomic orderings.
The relative developer-friendliness of sequential consistency doesn't come for free. Even on strongly-ordered platforms sequential consistency involves emitting memory fences.
In practice, sequential consistency is rarely necessary for program correctness. However sequential consistency is definitely the right choice if you're not confident about the other memory orders. Having your program run a bit slower than it needs to is certainly better than it running incorrectly! It's also mechanically trivial to downgrade atomic operations to have a weaker consistency later on. Just change SeqCst to Relaxed and you're done! Of course, proving that this transformation is correct is a whole other matter.
Relaxed
Relaxed accesses are the absolute weakest. They can be freely re-ordered and provide no happens-before relationship. Still, relaxed operations are still atomic. That is, they don't count as data accesses and any read-modify-write operations done to them occur atomically. Relaxed operations are appropriate for things that you definitely want to happen, but don't particularly otherwise care about. For instance, incrementing a counter can be safely done by multiple threads using a relaxed fetch_add if you're not using the counter to synchronize any other accesses.
There's rarely a benefit in making an operation relaxed on strongly-ordered platforms, since they usually provide release-acquire semantics anyway. However relaxed operations can be cheaper on weakly-ordered platforms.
Pattern matching
Patterns come in two forms: refutable and irrefutable.
Patterns that will match for any possible value passed are irrefutable. An example would be x in the statement let x = 5; because x matches anything and therefore cannot fail to match.
(Meaning it always will have a match.)
Patterns that can fail to match for some possible value are refutable. An example would be Some(x) in the expression if let Some(x) = a_value because if the value in the a_value variable is None rather than Some, the Some(x) pattern will not match.
Pattern matching type
let- only irrefutable- fn param, closure - only irrefutable
matchexp - accept refutable and irrefutableif letexp - accept refutable and irrefutablewhile letexp - accept refutable and irrefutableforexp - only irrefutable
let
#![allow(unused)] fn main() { struct Point {x: isize, y: isize}; let (a, b) = (1, 2); let Point {x, y} = Point {x:3, y:4}; assert_eq!(3, x); assert_eq!(4, y); }
No need to write ref?
Compiler helps you adding ref when matching references with
non-references like expressions.
#![allow(unused)] fn main() { let x: Option<String> = Some("hello".into()); match &x { Some(s) => println!("{}", s), // nothing moves here, `s` is a &String, // the same as `Some(ref s) => ...`, with `ref` added by compiler behind the scene None => println!("nothing") } println!("{}", x.unwrap()); // x still owns the String }
Smart pointers
Smart pointers allow you to store data on the heap rather than the stack. What remains on the stack is the pointer to the heap data.
Box<T>for allocating values on the heapRc<T>, a reference counting type that enables multiple ownershipRef<T>andRefMut<T>, accessed throughRefCell<T>, a type that enforces the borrowing rules at runtime instead of compile time
#![allow(unused)] fn main() { let s_on_stack: Box<&str> = Box::new("hello"); // string is still on stack let s_on_heap: Box<str> = Box::from("hello"); // string is copied onto heap println!("s_on_stack = {}", s_on_stack); println!("s_on_heap = {}", s_on_heap); }
Using Deref trait to auto dereference
use std::ops::Deref; struct MySmartPointer<T>{hold: T} impl<T> MySmartPointer<T> { fn new(hold: T) -> MySmartPointer<T> { MySmartPointer{hold} } } impl<T> Deref for MySmartPointer<T> { type Target = T; fn deref(&self) -> &T { &self.hold } } // using it struct User { name: &'static str } impl User { fn print_name(&self) { println!("My name is {}", self.name); } } fn main() { let user_pointer = MySmartPointer::new(User {name: "Alex"}); user_pointer.print_name(); // auto deref }
Using Box for unknown size type
#[derive(Debug)] enum List { Cons(i32, List), Nil, } use crate::List::{Cons, Nil}; fn main() { let list = Cons(1, Cons(2, Cons(3, Nil))); println!("{:?}", list); // recursive type has infinite size, won't compile }
Above code won't compile as Rust cannot know the size of a List as it is recursive. Now we can use Box<> to make it's size known at compile time.
#[derive(Debug)] enum List { Cons(i32, Box<List>), Nil, } use crate::List::{Cons, Nil}; fn main() { let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil)))))); println!("{:?}", list); }
String
char
Actually a 4-byte fixed size or u32 type of value.
#![allow(unused)] fn main() { let tao: char = '道'; println!("'道' as u32: {}", tao as u32); // 36947 char is basically u32 size unicode println!("U+{:x}", tao as u32); // U+9053 - output in 0x or hexadecimal(16) format println!("{}", tao.escape_unicode()); // \u{9053} println!("{}", char::from(65)); // from a u8 -> 'A' println!("{}", std::char::from_u32(0x9053).unwrap()); // from a u32 println!("{}", std::char::from_u32(36947).unwrap()); // from a u32 println!("{}", std::char::from_u32(1234567).unwrap_or('_')); // not every u32 is a char // noticing a char uses 4-byte in memory but not all the space is always used assert_eq!(3, tao.len_utf8()); // effective data length in byte assert_eq!(4, std::mem::size_of_val(&tao)); }
String
String is basically a Vec<u8>.
Other type:
Cstr/CstringOsStr/OsStringPath/PathBuf
#![allow(unused)] fn main() { let tao = std::str::from_utf8(&[0xe9u8, 0x81u8, 0x93u8]).unwrap(); println!("{}", tao); let tao = String::from("\u{9053}"); println!("{}", tao); }
A char like String might not be a char
A single "char" looking thing - like ❤️ - doesn't means it is a valid char. Some of those single looking characters needs more than
one char or code points to be represented:
#![allow(unused)] fn main() { assert_eq!(6, String::from("❤️").len()); // length in byte assert_eq!(6, std::mem::size_of_val(String::from("❤️").as_str())); // same calculation as above assert_eq!(2, String::from("❤️").chars().count()); // how many `code points` - is 2? // as ❤️ takes 2 code points , we can't assign it to a char // let heart = '❤️'; // This won't work assert_eq!(1, String::from("道").chars().count()); // 道 can be defined as a char as it only has 1 code point assert_eq!('道', String::from("道").chars().next().unwrap()); assert_eq!(3, String::from("道").len()); assert_eq!(3, std::mem::size_of_val(String::from("道").as_str())); }
'é' is not 'é'
As always, remember that a human intuition for 'character' may not map to Unicode's definitions. For example, despite looking similar, the 'é' character is one Unicode code point while 'é' is two Unicode code points:
#![allow(unused)] fn main() { assert_eq!(1, String::from("é").chars().count()); // '\u{00e9}' -> latin small letter e with acute assert_eq!(2, String::from("é").chars().count()); // '\u{0065}' + '\u{0301}' -> U+0065: 'latin small letter e', U+0301: 'combining acute accent' // They look the same in editor but have different code points ?! }
Note for tokio dev
Frequently used command:
# Run a single integration test
cargo test --test tcp_into_std
# Run a single doc test
cargo test --doc net::tcp::stream::TcpStream::into_std
# Format code
rustfmt --edition 2018 $(find . -name '*.rs' -print)
SpinLock implementation
Naive unsafe implementation
#![allow(unused)] fn main() { use std::sync::atomic::AtomicBool; use std::sync::atomic::Ordering::{Acquire, Release}; use std::cell::UnsafeCell; pub struct SpinLockUnsafe<T> { locked: AtomicBool, value: UnsafeCell<T>, } unsafe impl<T> Sync for SpinLockUnsafe<T> where T: Send {} impl<T> SpinLockUnsafe<T> { pub const fn new(value: T) -> Self { Self { locked: AtomicBool::new(false), value: UnsafeCell::new(value), } } pub fn lock(&self) -> &mut T { while self.locked.swap(true, Acquire) { std::hint::spin_loop(); } unsafe { &mut *self.value.get() } } /// Safety: The &mut T from lock() must be gone! /// (And no cheating by keeping reference to fields of that T around!) pub unsafe fn unlock(&self) { self.locked.store(false, Release); } } }
Better safe version and much easier to use
With the help of a Guard trick we let unlock be triggered during a drop on a Guard.
Interesting pattern.
#![allow(unused)] fn main() { use std::sync::atomic::AtomicBool; use std::sync::atomic::Ordering::{Acquire, Release}; use std::cell::UnsafeCell; use std::ops::{Deref, DerefMut}; /// To be able to provide a fully safe interface, we need to tie the unlocking operation to /// the end of the &mut T. We can do that by wrapping this reference in our own type that /// behaves like a reference, but also implements the Drop trait to do something when it is dropped. /// /// Such a type is often called a guard, as it effectively guards the state of the lock, /// and stays responsible for that state until it is dropped. pub struct Guard<'a, T> { lock: &'a SpinLock<T>, } pub struct SpinLock<T> { locked: AtomicBool, value: UnsafeCell<T>, } unsafe impl<T> Sync for SpinLock<T> where T: Send {} impl<T> SpinLock<T> { pub const fn new(value: T) -> Self { Self { locked: AtomicBool::new(false), value: UnsafeCell::new(value), } } pub fn lock(&self) -> Guard<T> { while self.locked.swap(true, Acquire) { std::hint::spin_loop(); } Guard { lock: self } } } impl<T> Deref for Guard<'_, T> { type Target = T; fn deref(&self) -> &T { // Safety: The very existence of this Guard // guarantees we've exclusively locked the lock. unsafe { &*self.lock.value.get() } } } impl<T> DerefMut for Guard<'_, T> { fn deref_mut(&mut self) -> &mut T { // Safety: The very existence of this Guard // guarantees we've exclusively locked the lock. unsafe { &mut *self.lock.value.get() } } } impl<T> Drop for Guard<'_, T> { fn drop(&mut self) { self.lock.locked.store(false, Release); } } }
Resources
Good posts and links
- Rust: A unique perspective - Matt Brubeck
- What Are Tokio and Async IO All About? - Manish Goregaokar
- Async: What is blocking? - Alice Ryhl
Network Programming
http://beej.us/guide/bgnet/html/
Two Types of Internet Sockets
SOCK_STREAM-> TCPSOCK_DGRAM-> UDP, may lost, may out of order, but fast
Layered Network Model (Data Encapsulation)
- Application Layer (telnet, ftp, etc.)
- Host-to-Host Transport Layer (TCP, UDP) - port number (16-bit number)
- Internet Layer (IP and routing)
- Network Access Layer (Ethernet, wi-fi, or whatever)
See how much work there is in building a simple packet? All you have to do for stream sockets is send() the data out.
All you have to do for datagram sockets is encapsulate the packet in the method of your choosing and sendto() it out. The kernel builds the Transport Layer and Internet Layer on for you and the hardware does the Network Access Layer. Ah, modern technology.
System calls
bind() - What port am I on?
struct addrinfo hints, *res;
int sockfd;
// first, load up address structs with getaddrinfo():
memset(&hints, 0, sizeof hints);
hints.ai_family = AF_UNSPEC; // use IPv4 or IPv6, whichever
hints.ai_socktype = SOCK_STREAM;
hints.ai_flags = AI_PASSIVE; // fill in my IP for me
getaddrinfo(NULL, "3490", &hints, &res);
// make a socket:
sockfd = socket(res->ai_family, res->ai_socktype, res->ai_protocol);
// bind it to the port we passed in to getaddrinfo():
bind(sockfd, res->ai_addr, res->ai_addrlen);
connect() - Hey, you!
struct addrinfo hints, *res;
int sockfd;
// first, load up address structs with getaddrinfo():
memset(&hints, 0, sizeof hints);
hints.ai_family = AF_UNSPEC;
hints.ai_socktype = SOCK_STREAM;
getaddrinfo("www.example.com", "3490", &hints, &res);
// make a socket:
sockfd = socket(res->ai_family, res->ai_socktype, res->ai_protocol);
// connect!
connect(sockfd, res->ai_addr, res->ai_addrlen);
Also, notice that we didn’t call bind(). Basically, we don’t care about our local port number; we only care where we’re going (the remote port). The kernel will choose a local port for us, and the site we connect to will automatically get this information from us. No worries.
listen() - Keep on answering stuff
int listen(int sockfd, int backlog);
sockfd is the usual socket file descriptor from the socket() system call. backlog is the number of connections allowed on the incoming queue. What does that mean? Well, incoming connections are going to wait in this queue until you accept() them and this is the limit on how many can queue up. Most systems silently limit this number to about 20; you can probably get away with setting it to 5 or 10.
Well, as you can probably imagine, we need to call bind() before we call listen() so that the server is running on a specific port.
accept() - "Thank you for calling port 3490."
#include <sys/types.h>
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
You call accept() and you tell it to get the pending connection. It’ll return to you a brand new socket file descriptor to use for this single connection! That’s right, suddenly you have two socket file descriptors for the price of one! The original one is still listening for more new connections, and the newly created one is finally ready to send() and recv()
send() and recv() - Talk to me, baby!
For UDP - sendto() and recvfrom().
int send(int sockfd, const void *msg, int len, int flags);
Example:
char *msg = "Beej was here!";
int len, bytes_sent;
.
.
len = strlen(msg);
bytes_sent = send(sockfd, msg, len, 0);
.
.
Remember, if the value returned by send() doesn’t match the value in len, it’s up to you to send the rest of the string. The good news is this: if the packet is small (less than 1K or so) it will probably manage to send the whole thing all in one go.
The recv() call is similar in many respects:
int recv(int sockfd, void *buf, int len, int flags);
recv() returns the number of bytes actually read into the buffer, or -1 on error (with errno set, accordingly).
Wait! recv() can return 0. This can mean only one thing: the remote side has closed the connection on you! A return value of 0 is recv()’s way of letting you know this has occurred.
int sendto(int sockfd, const void *msg, int len, unsigned int flags, const struct sockaddr *to, socklen_t tolen);
int recvfrom(int sockfd, void *buf, int len, unsigned int flags,struct sockaddr *from, int *fromlen);
close() and shutdown() —Get outta my face!
Examples!!!
/*
** server.c -- a stream socket server demo
*/
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <arpa/inet.h>
#include <sys/wait.h>
#include <signal.h>
#define PORT "3490" // the port users will be connecting to
#define BACKLOG 10 // how many pending connections queue will hold
void sigchld_handler(int s)
{
// waitpid() might overwrite errno, so we save and restore it:
int saved_errno = errno;
while(waitpid(-1, NULL, WNOHANG) > 0);
errno = saved_errno;
}
// get sockaddr, IPv4 or IPv6:
void *get_in_addr(struct sockaddr *sa)
{
if (sa->sa_family == AF_INET) {
return &(((struct sockaddr_in*)sa)->sin_addr);
}
return &(((struct sockaddr_in6*)sa)->sin6_addr);
}
int main(void)
{
int sockfd, new_fd; // listen on sock_fd, new connection on new_fd
struct addrinfo hints, *servinfo, *p;
struct sockaddr_storage their_addr; // connector's address information
socklen_t sin_size;
struct sigaction sa;
int yes=1;
char s[INET6_ADDRSTRLEN];
int rv;
memset(&hints, 0, sizeof hints);
hints.ai_family = AF_UNSPEC;
hints.ai_socktype = SOCK_STREAM;
hints.ai_flags = AI_PASSIVE; // use my IP
if ((rv = getaddrinfo(NULL, PORT, &hints, &servinfo)) != 0) {
fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(rv));
return 1;
}
// loop through all the results and bind to the first we can
for(p = servinfo; p != NULL; p = p->ai_next) {
if ((sockfd = socket(p->ai_family, p->ai_socktype,
p->ai_protocol)) == -1) {
perror("server: socket");
continue;
}
if (setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &yes,
sizeof(int)) == -1) {
perror("setsockopt");
exit(1);
}
if (bind(sockfd, p->ai_addr, p->ai_addrlen) == -1) {
close(sockfd);
perror("server: bind");
continue;
}
break;
}
freeaddrinfo(servinfo); // all done with this structure
if (p == NULL) {
fprintf(stderr, "server: failed to bind\n");
exit(1);
}
if (listen(sockfd, BACKLOG) == -1) {
perror("listen");
exit(1);
}
sa.sa_handler = sigchld_handler; // reap all dead processes
sigemptyset(&sa.sa_mask);
sa.sa_flags = SA_RESTART;
if (sigaction(SIGCHLD, &sa, NULL) == -1) {
perror("sigaction");
exit(1);
}
printf("server: waiting for connections...\n");
while(1) { // main accept() loop
sin_size = sizeof their_addr;
new_fd = accept(sockfd, (struct sockaddr *)&their_addr, &sin_size);
if (new_fd == -1) {
perror("accept");
continue;
}
inet_ntop(their_addr.ss_family,
get_in_addr((struct sockaddr *)&their_addr),
s, sizeof s);
printf("server: got connection from %s\n", s);
if (!fork()) { // this is the child process
close(sockfd); // child doesn't need the listener
if (send(new_fd, "Hello, world!", 13, 0) == -1)
perror("send");
close(new_fd);
exit(0);
}
close(new_fd); // parent doesn't need this
}
return 0;
}
/*
** client.c -- a stream socket client demo
*/
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <netdb.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#define PORT "3490" // the port client will be connecting to
#define MAXDATASIZE 100 // max number of bytes we can get at once
// get sockaddr, IPv4 or IPv6:
void *get_in_addr(struct sockaddr *sa)
{
if (sa->sa_family == AF_INET) {
return &(((struct sockaddr_in*)sa)->sin_addr);
}
return &(((struct sockaddr_in6*)sa)->sin6_addr);
}
int main(int argc, char *argv[])
{
int sockfd, numbytes;
char buf[MAXDATASIZE];
struct addrinfo hints, *servinfo, *p;
int rv;
char s[INET6_ADDRSTRLEN];
if (argc != 2) {
fprintf(stderr,"usage: client hostname\n");
exit(1);
}
memset(&hints, 0, sizeof hints);
hints.ai_family = AF_UNSPEC;
hints.ai_socktype = SOCK_STREAM;
if ((rv = getaddrinfo(argv[1], PORT, &hints, &servinfo)) != 0) {
fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(rv));
return 1;
}
// loop through all the results and connect to the first we can
for(p = servinfo; p != NULL; p = p->ai_next) {
if ((sockfd = socket(p->ai_family, p->ai_socktype,
p->ai_protocol)) == -1) {
perror("client: socket");
continue;
}
if (connect(sockfd, p->ai_addr, p->ai_addrlen) == -1) {
close(sockfd);
perror("client: connect");
continue;
}
break;
}
if (p == NULL) {
fprintf(stderr, "client: failed to connect\n");
return 2;
}
inet_ntop(p->ai_family, get_in_addr((struct sockaddr *)p->ai_addr),
s, sizeof s);
printf("client: connecting to %s\n", s);
freeaddrinfo(servinfo); // all done with this structure
if ((numbytes = recv(sockfd, buf, MAXDATASIZE-1, 0)) == -1) {
perror("recv");
exit(1);
}
buf[numbytes] = '\0';
printf("client: received '%s'\n",buf);
close(sockfd);
return 0;
}
Blocking
Lots of functions block. accept() blocks. All the recv() functions block. The reason they can do this is because they’re allowed to. When you first create the socket descriptor with socket(), the kernel sets it to blocking. If you don’t want a socket to be blocking, you have to make a call to fcntl():
#include <unistd.h>
#include <fcntl.h>
.
.
sockfd = socket(PF_INET, SOCK_STREAM, 0);
fcntl(sockfd, F_SETFL, O_NONBLOCK);
.
.
By setting a socket to non-blocking, you can effectively “poll” the socket for information. If you try to read from a non-blocking socket and there’s no data there, it’s not allowed to block — it will return -1 and errno will be set to EAGAIN or EWOULDBLOCK.
(Wait—it can return EAGAIN or EWOULDBLOCK? Which do you check for? The specification doesn’t actually specify which your system will return, so for portability, check them both.)
Generally speaking, however, this type of polling is a bad idea. If you put your program in a busy-wait looking for data on the socket, you’ll suck up CPU time like it was going out of style. A more elegant solution for checking to see if there’s data waiting to be read comes in the following section on poll().
poll() — Synchronous I/O Multiplexing
What you really want to be able to do is somehow monitor a bunch of sockets at once and then handle the ones that have data ready. This way you don’t have to continously poll all those sockets to see which are ready to read.
So how can you avoid polling? Not slightly ironically, you can avoid polling by using the poll() system call. In a nutshell, we’re going to ask the operating system to do all the dirty work for us, and just let us know when some data is ready to read on which sockets. In the meantime, our process can go to sleep, saving system resources.
The general gameplan is to keep an array of struct pollfds with information about which socket descriptors we want to monitor, and what kind of events we want to monitor for. The OS will block on the poll() call until one of those events occurs (e.g. “socket ready to read!”) or until a user-specified timeout occurs.
Usefully, a listen()ing socket will return “ready to read” when a new incoming connection is ready to be accept()ed.
That’s enough banter. How do we use this?
#include <poll.h>
int poll(struct pollfd fds[], nfds_t nfds, int timeout);
fds is our array of information (which sockets to monitor for what), nfds is the count of elements in the array, and timeout is a timeout in milliseconds. It returns the number of elements in the array that have had an event occur.
Let’s have a look at that struct:
struct pollfd {
int fd; // the socket descriptor
short events; // bitmap of events we're interested in
short revents; // when poll() returns, bitmap of events that occurred
};
So we’re going to have an array of those, and we’ll see the fd field for each element to a socket descriptor we’re interested in monitoring. And then we’ll set the events field to indicate the type of events we’re interested in.
The events field is the bitwise-OR of the following:
| Macro | Description |
|---|---|
POLLIN | Alert me when data is ready to recv() on this socket. |
POLLOUT | Alert me when I can send() data to this socket without blocking. |
Once you have your array of struct pollfds in order, then you can pass it to poll(), also passing the size of the array, as well as a timeout value in milliseconds. (You can specify a negative timeout to wait forever.)
After poll() returns, you can check the revents field to see if POLLIN or POLLOUT is set, indicating that event occurred.
(There’s actually more that you can do with the poll() call. See the poll() man page, below, for more details.)
Here’s an example28 where we’ll wait 2.5 seconds for data to be ready to read from standard input, i.e. when you hit RETURN:
#include <stdio.h>
#include <poll.h>
int main(void)
{
struct pollfd pfds[1]; // More if you want to monitor more
pfds[0].fd = 0; // Standard input
pfds[0].events = POLLIN; // Tell me when ready to read
// If you needed to monitor other things, as well:
//pfds[1].fd = some_socket; // Some socket descriptor
//pfds[1].events = POLLIN; // Tell me when ready to read
printf("Hit RETURN or wait 2.5 seconds for timeout\n");
int num_events = poll(pfds, 1, 2500); // 2.5 second timeout
if (num_events == 0) {
printf("Poll timed out!\n");
} else {
int pollin_happened = pfds[0].revents & POLLIN;
if (pollin_happened) {
printf("File descriptor %d is ready to read\n", pfds[0].fd);
} else {
printf("Unexpected event occurred: %d\n", pfds[0].revents);
}
}
return 0;
}
Notice again that poll() returns the number of elements in the pfds array for which events have occurred. It doesn’t tell you which elements in the array (you still have to scan for that), but it does tell you how many entries have a non-zero revents field (so you can stop scanning after you find that many).
How can we put it all together into a chat server that you can telnet/nc to?
What we’ll do is start a listener socket, and add it to the set of file descriptors to poll(). (It will show ready-to-read when there’s an incoming connection.)
Then we’ll add new connections to our struct pollfd array. And we’ll grow it dynamically if we run out of space.
When a connection is closed, we’ll remove it from the array.
And when a connection is ready-to-read, we’ll read the data from it and send that data to all the other connections so they can see what the other users typed.
So give this poll server a try. Run it in one window, then telnet localhost 9034 from a number of other terminal windows. You should be able to see what you type in one window in the other ones (after you hit RETURN).
Not only that, but if you hit CTRL-] and type quit to exit telnet, the server should detect the disconnection and remove you from the array of file descriptors.
/*
** pollserver.c -- a cheezy multiperson chat server
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <netdb.h>
#include <poll.h>
#define PORT "9034" // Port we're listening on
// Get sockaddr, IPv4 or IPv6:
void *get_in_addr(struct sockaddr *sa)
{
if (sa->sa_family == AF_INET) {
return &(((struct sockaddr_in*)sa)->sin_addr);
}
return &(((struct sockaddr_in6*)sa)->sin6_addr);
}
// Return a listening socket
int get_listener_socket(void)
{
int listener; // Listening socket descriptor
int yes=1; // For setsockopt() SO_REUSEADDR, below
int rv;
struct addrinfo hints, *ai, *p;
// Get us a socket and bind it
memset(&hints, 0, sizeof hints);
hints.ai_family = AF_UNSPEC;
hints.ai_socktype = SOCK_STREAM;
hints.ai_flags = AI_PASSIVE;
if ((rv = getaddrinfo(NULL, PORT, &hints, &ai)) != 0) {
fprintf(stderr, "selectserver: %s\n", gai_strerror(rv));
exit(1);
}
for(p = ai; p != NULL; p = p->ai_next) {
listener = socket(p->ai_family, p->ai_socktype, p->ai_protocol);
if (listener < 0) {
continue;
}
// Lose the pesky "address already in use" error message
setsockopt(listener, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(int));
if (bind(listener, p->ai_addr, p->ai_addrlen) < 0) {
close(listener);
continue;
}
break;
}
freeaddrinfo(ai); // All done with this
// If we got here, it means we didn't get bound
if (p == NULL) {
return -1;
}
// Listen
if (listen(listener, 10) == -1) {
return -1;
}
return listener;
}
// Add a new file descriptor to the set
void add_to_pfds(struct pollfd *pfds[], int newfd, int *fd_count, int *fd_size)
{
// If we don't have room, add more space in the pfds array
if (*fd_count == *fd_size) {
*fd_size *= 2; // Double it
*pfds = realloc(*pfds, sizeof(**pfds) * (*fd_size));
}
(*pfds)[*fd_count].fd = newfd;
(*pfds)[*fd_count].events = POLLIN; // Check ready-to-read
(*fd_count)++;
}
// Remove an index from the set
void del_from_pfds(struct pollfd pfds[], int i, int *fd_count)
{
// Copy the one from the end over this one
pfds[i] = pfds[*fd_count-1];
(*fd_count)--;
}
// Main
int main(void)
{
int listener; // Listening socket descriptor
int newfd; // Newly accept()ed socket descriptor
struct sockaddr_storage remoteaddr; // Client address
socklen_t addrlen;
char buf[256]; // Buffer for client data
char remoteIP[INET6_ADDRSTRLEN];
// Start off with room for 5 connections
// (We'll realloc as necessary)
int fd_count = 0;
int fd_size = 5;
struct pollfd *pfds = malloc(sizeof *pfds * fd_size);
// Set up and get a listening socket
listener = get_listener_socket();
if (listener == -1) {
fprintf(stderr, "error getting listening socket\n");
exit(1);
}
// Add the listener to set
pfds[0].fd = listener;
pfds[0].events = POLLIN; // Report ready to read on incoming connection
fd_count = 1; // For the listener
// Main loop
for(;;) {
int poll_count = poll(pfds, fd_count, -1);
if (poll_count == -1) {
perror("poll");
exit(1);
}
// Run through the existing connections looking for data to read
for(int i = 0; i < fd_count; i++) {
// Check if someone's ready to read
if (pfds[i].revents & POLLIN) { // We got one!!
if (pfds[i].fd == listener) {
// If listener is ready to read, handle new connection
addrlen = sizeof remoteaddr;
newfd = accept(listener,
(struct sockaddr *)&remoteaddr,
&addrlen);
if (newfd == -1) {
perror("accept");
} else {
add_to_pfds(&pfds, newfd, &fd_count, &fd_size);
printf("pollserver: new connection from %s on "
"socket %d\n",
inet_ntop(remoteaddr.ss_family,
get_in_addr((struct sockaddr*)&remoteaddr),
remoteIP, INET6_ADDRSTRLEN),
newfd);
}
} else {
// If not the listener, we're just a regular client
int nbytes = recv(pfds[i].fd, buf, sizeof buf, 0);
int sender_fd = pfds[i].fd;
if (nbytes <= 0) {
// Got error or connection closed by client
if (nbytes == 0) {
// Connection closed
printf("pollserver: socket %d hung up\n", sender_fd);
} else {
perror("recv");
}
close(pfds[i].fd); // Bye!
del_from_pfds(pfds, i, &fd_count);
} else {
// We got some good data from a client
for(int j = 0; j < fd_count; j++) {
// Send to everyone!
int dest_fd = pfds[j].fd;
// Except the listener and ourselves
if (dest_fd != listener && dest_fd != sender_fd) {
if (send(dest_fd, buf, nbytes, 0) == -1) {
perror("send");
}
}
}
}
} // END handle data from client
} // END got ready-to-read from poll()
} // END looping through file descriptors
} // END for(;;)--and you thought it would never end!
return 0;
}
An interesting task to is to swich poll above to epoll on Linux or kqueue on Mac.
For now, a similar server implement in Rust could be like:
use std::collections::HashMap; use std::io::{Read, Write}; use std::net::{Shutdown, SocketAddr, TcpListener, TcpStream}; use std::sync::mpsc::{channel, Receiver, Sender}; use std::sync::{Arc, Mutex}; use std::thread; fn handle_client( mut stream: TcpStream, sender_agent: Sender<(SocketAddr, String)>, // agent sender for broadcast message to others receiver: Receiver<String>, // broadcast receiver to get message from other client peer_addr: SocketAddr, // client addr sender_map: Arc<Mutex<HashMap<SocketAddr, Sender<String>>>>, // handle for remove disconnected senders from sender_map ) { let mut data = [0 as u8; 50]; // using 50 byte buffer let mut stream_clone = stream.try_clone().expect("clone failed..."); std::thread::spawn(move || { while match receiver.recv() { Ok(msg) => { stream_clone.write(msg.as_bytes()).unwrap(); true } Err(e) => { println!("Client {} disconnected. Message: {}", peer_addr, e); false } } {} }); while match stream.read(&mut data) { Ok(0) => { // Stream ended as client closed, clean up stuff here sender_map.lock().unwrap().remove(&peer_addr); false } Ok(size) => { // echo everything! // stream.write(&data[0..size]).unwrap(); let to_send = std::str::from_utf8(&data[0..size]).unwrap_or("?").into(); match sender_agent.send((peer_addr.clone(), to_send)) { Ok(_) => true, Err(e) => { println!("{}", e); sender_map.lock().unwrap().remove(&peer_addr); false } } } Err(_) => { println!( "An error occurred, terminating connection with {}", stream.peer_addr().unwrap() ); stream.shutdown(Shutdown::Both).unwrap(); false } } {} } fn main() { let listener = TcpListener::bind("0.0.0.0:3333").unwrap(); // accept connections and process them, spawning a new thread for each one println!("Server listening on port 3333"); let (sender_agent, recv_agent) = channel::<(SocketAddr, String)>(); let sender_map: Arc<Mutex<HashMap<SocketAddr, Sender<String>>>> = Arc::new(Mutex::new(HashMap::new())); let sender_map_copy = sender_map.clone(); // Agent thread thread::spawn(move || { while match recv_agent.recv() { Ok((addr, msg)) => { print!("[{}]: {}", &addr, msg.as_str()); for (key, sender_in_map) in sender_map_copy.lock().unwrap().iter() { if key == &addr { continue; } match sender_in_map.send(format!("[{}]: {}", addr, msg)) { Ok(_) => {} Err(e) => println!("{}", e), } } true } Err(e) => { println!("{:?}", e); true } } {} }); for stream in listener.incoming() { let sender_agent_copy = sender_agent.clone(); let (sender_in_map, recv) = channel(); match stream { Ok(mut stream) => { let peer_addr = stream.peer_addr().unwrap(); println!("New connection: {}", peer_addr); stream .write(format!("Welcome {}\n", peer_addr).as_bytes()) .unwrap(); let sender_map_copy = sender_map.clone(); sender_map_copy .lock() .unwrap() .insert(peer_addr.clone(), sender_in_map.clone()); thread::spawn(move || { // connection succeeded handle_client(stream, sender_agent_copy, recv, peer_addr, sender_map_copy) }); } Err(e) => { println!("Error: {}", e); /* connection failed */ } } } // close the socket server drop(listener); }
♨️ Java
An interesting blog on some Java Features such as
DelayQueue StampedLock and Phaser
English,
Chinese
A video about Phaser and StampedLock
Scheduler stuff
@Test
public void a() throws Exception {
ExecutorService executor = Executors.newSingleThreadExecutor();
Runnable runnable =
() -> {
try {
while (true) {
System.out.println("Running");
Thread.sleep(1000);
}
} catch (InterruptedException e) {
System.out.println("Runnable interrupted");
} finally {
System.out.println("FINALLY");
}
};
Future<?> future = executor.submit(callable);
try {
future.get(3, TimeUnit.SECONDS); // blocking for 3 seconds
} catch (TimeoutException e) {
System.out.println("Timeout " + e);
// future will continue running even if we got a TimeoutException
} catch (InterruptedException | ExecutionException e) {
System.out.println("Interrupted");
}
Thread.sleep(3 * 1000);
System.out.println("END");
}
Output:
Running
Running
Running
Running
Timeout java.util.concurrent.TimeoutException
Running
Running
Running
END
Now if we do call cancel on the future, then
it works as expected.
@Test
public void b() throws Exception {
ExecutorService executor = Executors.newSingleThreadExecutor();
Runnable r =
() -> {
try {
while (true) {
System.out.println("Running");
Thread.sleep(1000);
}
} catch (InterruptedException e) {
System.out.println("Runnable interrupted");
} finally {
System.out.println("FINALLY");
}
};
Future<?> future = executor.submit(r);
try {
future.get(3, TimeUnit.SECONDS);
} catch (TimeoutException e) {
// To stop future running, we need to call cancel on it.
boolean c = future.cancel(true);
System.out.println("Timeout " + e);
} catch (InterruptedException | ExecutionException e) {
System.out.println("interrupted");
}
Thread.sleep(3 * 1000);
System.out.println("END");
}
Output
Running
Running
Running
Runnable interrupted
FINALLY
Timeout java.util.concurrent.TimeoutException
END
Some new_features learned
Video list:
- https://www.youtube.com/watch?v=q2T9NlROLqw
- https://www.youtube.com/watch?v=nlZe-y2XvQY
switch expression is better than switch statement
The switch in newer Java can be written as expressions, which
is much better than the statement as:
- statement needs to mutate stuff in order to have effect;
- easy to write wrong stuff when missing
break; - statement has no exhaustive check, but expression has :)
Also, when using switch statement, do not write the default if not
necessary as there is already exhaustive check.
Plus, there is a yeild if one wants to "return a value" from
a switch block.
List types can be immutable or mutable but difficult to tell
Generally, seems the old APIs prefer to return mutable stuff.
Mutable:
- Arrays.asList();
- stream.collect(Collectors.toList());
Immutable:
- List.of();
- stream.toList();
teeing as an interesting collector:
/--------\ (collect)
----teeing (collect) -----
\--------/ (collect)
For these type of operations, teeing could be a good candidate.
Also noticing these groupingBy, partitionBy like collectors,
can also take the last parameter in with another collector.
So this "collector of collectors (of collectors)" can be powerful
but becareful not going too deep!
Record data class is nice
- The simple/compact constructors in Records is nice, but do not use
thisthere as it just some code that runs before the real internal constructor is called. - Record fields are
final, so one can use the compact constructors to play with different initial fields values, and let the internal/canonical constructor to do the finalthis.x=xassignments. - Use local
Recordto represent Tuple might be a good idea especially the Tuple type do not need to be shared around.
sealed + permits classes and interfaces
Thus, the main motivation behind sealed classes/interfaces is to have the possibility for a superclass/interface to be widely accessible but not widely extensible.
- All permitted subclasses must belong to the same module as the sealed class.
- Every permitted subclass must explicitly extend the sealed class.
- Every permitted subclass must define a modifier: final, sealed, or non-sealed.
Pattern matching with switch is nice
public class Main {
public static String matchWithSwitch(Object in) {
return switch (in) {
case null -> "oh come on...";
case Integer i when i < 0 -> "got a negative number: " + i;
case Integer i -> "got a number:" + i;
case String s -> "got a string of length: " + s.length();
default -> "got something unknown";
};
}
}
CLI tools
Maybe try some other stuff another day
Probability and Statistics
Upon successful completion of this course, you will:
At a conceptual level:
- Master the basic concepts associated with
probability models. - Be able to translate models described in words to mathematical ones.
- Understand the main concepts and assumptions underlying
Bayesian and classical inference. - Obtain some familiarity with the range of applications of inference methods .
At a more technical level:
- Become familiar with basic and common
probability distributions. - Learn how to use
conditioningto simplify the analysis of complicated models. - Have facility manipulating
probability mass functions,densities, andexpectations. - Develop a solid understanding of the concept of
conditional expectationand its role in inference. - Understand the power of
laws of large numbersand be able to use them when appropriate. - Become familiar with the basic inference methodologies (for both
estimation and hypothesis testing) and be able to apply them. - Acquire a good understanding of two
basic stochastic processes(Bernoulli and Poisson) and their use in modeling. - Learn how to formulate simple dynamical models as
Markov chainsand analyze them.
Useful maths equations
Geometric series
\[ {\sum^{\infty }_{n = 0} r^n} = \frac 1 {1 - r} \quad \text{if } |r| < 1 \]
\[ {\sum^{\infty }_{n = 1} r^n} = \frac {r} {1 - r} \quad \text{if } |r| < 1 \]
\[ \frac{1}{2} + \frac{1}{4} + \frac{1}{8} + ... = \frac 1 2 {\sum^{\infty }_{n = 0} \frac{1}{2^n}} = \frac 1 2 \frac 1 {1-\frac 1 2} = 1 \]
integration by parts
\[ \int u \mathrm{d} v = uv - \int v \mathrm{d} u \]
Chapter 1 - Basics and Bayes' Rule
De Morgans' Law
-
\( (S \cap T)^c = S^c \cup T^c \) and \( (S \cup T)^c = S^c \cap T^c \)
-
\( (S^c \cap T^c)^c = S \cup T \)
Problem 4. Parking lot problem
Mary and Tom park their cars in an empty parking lot with 𝑛≥2 consecutive parking spaces (i.e, 𝑛 spaces in a row, where only one car fits in each space). Mary and Tom pick parking spaces at random; of course, they must each choose a different space. (All pairs of distinct parking spaces are equally likely.) What is the probability that there is at most one empty parking space between them?
View answer
- when first car is at head or tail, second car has 2 configurations for each case (gives 4 configurations)
- when first car is at head+1 or tail-1, second har has 3 configurations for each case (gives 6 configurations)
- when first car is at the rest of the place, second car has 4 configurations for each case, giving 4*(n-4) configurations
- the total number of all possible configurations is n*(n-1)
- so the answer should be (4*(n-4)+ 4 +6)/(n*(n-1))
3 Important tools
- Multiplication rule
- Total probability theorem
- Bayes' rule (-> inference)
Conditional probability
\[ P(A | B) = \frac{ P(A \cap B)}{ P(B)} \]
\[ P(A | B) P(B)= P(B | A) P(A) \]
\[ P(A | B) = \frac{ P(B | A) P(A) } { P(B | A) P(A) + P(B | A^C) P( A^C)} \]

Multiplication rule

Total probability theorem

\( P(B) = P(B | A) P(A) + P(B | A^C) P( A^C) \) can be generalized to:
\[ P(B) = \sum_{i} P(B | A_i) P(A_i) \quad \text{ given } \sum_i P(A_i) = 1 \]
Definition of independence:
\[ P(A \cap B) = P(A) \cdot P(B) \]
Which also implies \( P(B | A) = P(B); P(A | B) = P(A)\), and also implies \( P(A \cap B^C) = P(A) \cdot P(B^C) \).
Note that ìndependence has no relation related to disjoint.
Independence is a relation about information. It is important
to always keep in mind the intuitive meaning of independence.
Two events are independent if the occurrence of one event
does not change our beliefs about the other.
Conditional independence


Permutation & Combination
Permutation - pick r items out of n items, order matters:
\[
P = \frac{n!}{(n-r)!}
\]
Combination - pick r items out of n items, order does not matter:
\[
C = \frac{P}{r!} = \frac{n!}{(n-r)! \cdot r!}
\]
Number of subsets of n element:
\[
2^n
\]
\[ \sum_{k=0}^{n} \left( \begin{array}{c} n \\ k \end{array} \right) = 2^n \]
Number of possible outcomes of continuously toss a fair 6-faces dice for n times:
\[
6^n
\]
Binomial coefficient \( \left( \begin{array}{c} n \\ k \end{array} \right) \)
- n>=1 independent coin tosses
P(H)=p: \[ P(k \quad heads) = \left( \begin{array}{c} n \\ k \end{array} \right) p^k (1-p)^{n-k} \]
\[ \sum_{k=0}^{n} \left( \begin{array}{c} n \\ k \end{array} \right) p^k (1-p)^{n-k} = 1 \]
Multinomial coefficient

Chapter 2 - Discrete Random Variables
Random variable examples:
- Bernoulli
- Uniform
- Binomial
- Geometric
Random Variables
Random variables can be understand as a function that
transfers a random selection of a sample, into a
numeric value.
随机变量可以看作是一个函数!!!
Notation: random variable X, numerical value x
Probability Mass Function (PMF)
PMF also called as probablility distribution.
Bernoulli
- X = 1, with probability p,
- X = 0, with probability 1 - p.
E[X] = p;
var(X) = E[X^2] - (E[X])^2 = p(1-p)
Uniform
- each outcome have the same probability
- h(X) = 1 / (b-a+1)
- E[X] = (a + b) / 2
- var(X) = 1/12 * (b-a) * (b-a+2)
For the continuous case:
- E[X] = (a + b) / 2
- var(X) = 1/12 * (b-a)^2
Binomial
nindependent tosses of a coin with P(Heads)=p, withX= number of heads observed.
E(X) = E(X1) + E(X2) ... + E(Xn) = p + p + p + ... p = n * p
var(X) = var(X1 + X2 + ...) = var(X1) + var(X2)... = n * var(X1) = n * BernoulliVar = np(1-p)
Note above: because of independence.
Geometric
- infinitely many independent tosses of a coin,
P(Heads)=p,
X= number of tosses until the first Heads. \( P(X=k) = (1-p)^{k-1} p \). If p=0.5, then it is like 1/2, 1/4, 1/8 ... - model the time we have to wait until something happens, especially for the continuous case.
Memorylessness
- E[X] = 1 / p
- var(X) = (1-p)/p^2
For the continuous case:
- E[x] = 1/lambda
- var(X) = 1/lambda^2


Variance


📝 Vi editor tips
Moving
w move to beginning of next word
b move to previous beginning of word
e move to end of word
ge move to previous end of word
gg move to first line
G move to last line
12gg or 12G moves to line 12
0 move to beginning of line
$ move to end of line
_ 🔥 move to first non-blank character of the line
g_ move to last non-blank character of the line
g; 🔥 jump to the place of last edit. can be quite helpful while debugging or editing files.
% move to the matching part of a (, [ or {
[{ move to the first enclosure of { above
Ctrl-D 🔥 move half-page down
Ctrl-U 🔥 move half-page up
Ctrl-B page up
Ctrl-F page down
Ctrl-O 🔥 jump to last (older) cursor position
Ctrl-I 🔥 jump to next cursor position (after Ctrl-O)
Ctrl-Y move view pane up
Ctrl-E move view pane down
n 🔥 next matching search pattern
N previous matching search pattern
* 🔥 next whole word under cursor
# previous whole word under cursor
g* next matching search (not whole word) pattern under cursor
g# previous matching search (not whole word) pattern under cursor
gd 🔥 go to definition/first occurrence of the word under cursor
fX fall onto to next 'X', in the same line (X is any character)
FX fall to previous 'X' (f and F put the cursor on X)
tX til next 'X' (similar to above, but cursor is before X)
TX til previous 'X' (cursor is behind X)
J join, move next line below to the end of current line (but adds a space)
Jx join like above, and remove the added space.
For ideavimrc, one can set up some extra actions such as moving to previous or next error locatoin
nnoremap g[ :action GotoPreviousError<CR>
nnoremap g] :action GotoNextError<CR>
Editing
i, a, A, o, O into insert mode in different locations
r, R replace char or word
ci" change inside quotes
di" delete inside quotes
ca" change around quotes, include quotes
da" delete around quotes
d0 delete till be beginning of current line
d$, D delete till the end of current line
u undo
Ctrl-r redo
>> indent the current line
>iB, >i} indent the current Block
,, (2 comma) 🔧 customized to add a ; at the end of the line
inoremap <leader>, <C-o>A;<ESC>
innoremap <leader>, A;<ESC>
vim-surround
ysiw" add " surround in word
cs"' change surround " to '
ds" delete surround "
ReplaceWithRegister
griw Replace in word by previously yanked or deleted stuff
gr$ Replace from the cursor position to the end of the line
Folding
zo Open one fold under the cursor.
zO Open folds, recursively.
zc Close one fold under the cursor.
zC Close folds, recursively.
zM Close all folds: set 'foldlevel' to 0. 'foldenable' will be set.
zR Open all folds. This sets 'foldlevel' to highest fold level.
For ideavim, set up as such:
nnoremap zC :action CollapseRegionRecursively<CR>
nnoremap zO :action ExpandRegionRecursively<CR>
Options
:noh turn off highlight
:set hls highlight all matching phrases
:set ic set ignore case for search
:set noic set not ignore case again
:set invic use inv to invert the option - f.g. ic here
Search stuff
/ find pattern
n go to next found pattern
:! grep -rin -A2 -B2 --color --include=\*.md . -e 'yank'
use a grep command to show what md files from
current directory contains word 'yank' or 'Yank'
r: recursive, n: show line number, i: ignore case
Replace/Substitue stuff
To substitute new for the first old in a line type
~~~ cmd
:s/old/new
~~~
To substitute new for all 'old's on a line type
~~~ cmd
:s/old/new/g
~~~
To substitute phrases between two line #'s type
~~~ cmd
:#,#s/old/new/g
~~~
To substitute all occurrences in the file type
~~~ cmd
:%s/old/new/g
~~~
To ask for confirmation each time add 'c'
~~~ cmd
:%s/old/new/gc
~~~
Copy Paste stuff
How to select a word, copy it and replace another word.
yiw Yank inner word (copy word under cursor, say "first").
... Move the cursor to another word (say "second").
viwp Select "second", then replace it with "first".
... Move the cursor to another word (say "third").
viw"0p Select "third", then replace it with "first".
🔥 Copy a word and paste it over other words:
yiw Yank inner word (copy word under cursor, say "first").
... Move the cursor to another word (say "second").
ciw Ctrl-R 0 Esc 🔥Change "second", replacing it with "first".
... Move the cursor to another word (say "third").
. Repeat the operation (change word and replace it with "first").
... Move the cursor to another word and press . to repeat the change.
Copy text in quotes, and paste it over other quoted text:
yi" Yank inner text (text containing cursor which is in quotes).
... Move the cursor to other quoted text.
ci" Ctrl-R 0 Esc 🔥Change the quoted text, replacing it with the copied text.
... Move the cursor to more quoted text.
. Repeat the operation (change the quoted text and replace it with the copy).
... Move the cursor to more quoted text and press . to repeat the change.
Copy a line and paste it over other lines:
yy Yank current line (say "first line").
... Move the cursor to another line (say "second line").
Vp Select "second line", then replace it with "first line".
... Move the cursor to another line (say "third line").
V"0p Select "third line", then replace it with "first line".
Deleting, changing and yanking text copies the affected text to the unnamed register (""). Yanking text also copies the text to register 0 ("0). So the command yiw copies the current word to "" and to "0.
yl /vy/xu Yank current character. Composing the yank operation with the so often used "one character to the right" motion
Window and Tab
Ctrl-W s split window horiontally, can be used with ctrlpvim after Ctrl-P to open file
Ctrl-W v split window vertically, can be used with ctrlpvim after Ctrl-P to open file
Ctrl-W l jump to the window on the right
Ctrl-W x switch current window with next one
gt move to the tab after
gT move to the tab before
gt3 move to tab number 3
Group change
Ctrl-V, then move to select, then Shift-<action>, then ESC
Commenting
With plugin:
- Plug 'scrooloose/nerdcommenter'
[count]<leader>cc |NERDCommenterComment| Comment out the current line or text selected in visual mode.
[count]<leader>cn |NERDCommenterNested| Same as cc but forces nesting.
[count]<leader>c<space> |NERDCommenterToggle| Comment Toggle
[count] gcc 🔧 comment toggle, need a special setup, see my mac-settings repo's config files.
For IntelliJ's ideavim plugin, add set commentary in it's config file.
If in IntelliJ with the ideavim plugin, use gcc to comment.
Turn off search highlight
:noh
Spell check with NeoVim
z= give suggestions
zg add it as a good word
zw add it as a wrong word
Plugin NERDTree
,t focus on tree view
Ctrl-t toggle tree view
Ctrl-j 🔧 customized - :NERDTreeFind
,n 🔧 customized - :NERDTreeFind
PlugIn CtrlP to find and open files
F5 refresh files
Ctrl-p open serach
Ctrl-p Ctrl-s/v open in new window
Ctrl-p Ctrl-t open in new tab
,p 🔧 only search in buffered files
# above command is customized via setting:
# nnoremap <leader>p :CtrlPBuffer<CR>
PlugIn VimTest
Plug 'vim-test/vim-test'
https://github.com/vim-test/vim-test
:TestNearest run nearest test
:TestFile run all test in file
:TestSuite run the whole test suite
:TestLast run last test
:TestVisit visit the test file from which you last run your tests
🔧 Customized COC shortcut
Ctrl-l 🔧 reformat file
Ctrl-space give suggestions
gb 🔧 go to definition
gy 🔧 go to type definition
gi 🔧 go to implementation
gr 🔧 references
gp go to previous issue
gå go to next issue
K show documentation
Tmux
Window and Pane
Ctrl-b c create window
Ctrl-b n/p go to next or previous window
Ctrl-b w list all windows
Ctrl-b 0/1.. go to window number 0/1/...
Ctrl-b % split horisontal pane
Ctrl-b " split vertical pane
Ctrl-b o go to next pane
Tmux Session
tmux new -s <name> create new session
Ctrl-b d detach session
Ctrl-b x kill current session
tmux ls list sessions
tmux kill-session -t [name]
tmux rename-session [-t current-name] [new-name]
Ctrl-b $ to rename session while in tmux
.ideavimrc
An .ideavimrc example which I have been using for a few years.
" .ideavimrc is a configuration file for IdeaVim plugin. It uses
" the same commands as the original .vimrc configuration.
" You can find a list of commands here: https://jb.gg/h38q75
" Find more examples here: https://jb.gg/share-ideavimrc
" Default key maps:
" https://github.com/JetBrains/ideavim/blob/master/src/main/java/com/maddyhome/idea/vim/package-info.java
" https://github.com/JetBrains/ideavim/blob/master/doc/IdeaVim%20Plugins.md
" set clipboard+=unnamedplus
" set <leader> to <space>
let mapleader = " "
" https://stackoverflow.com/questions/48885527/only-associate-register-0-with-system-clipboard-in-vim
nnoremap <leader>y "+y
vnoremap <leader>y "+y
nnoremap <leader>p "+p
vnoremap <leader>p "+p
" https://github.com/TheBlob42/idea-which-key?tab=readme-ov-file#installation
" install which-key IntelliJ plugin
set which-key
set notimeout
" install vim sneak IntelliJ plugin
set sneak
" install vim quickscope IntelliJ plugin, here I turned it off.
set noquickscope
"" -- Suggested options --
" Show a few lines of context around the cursor. Note that this makes the
" text scroll if you mouse-click near the start or end of the window.
set scrolloff=5
" Do incremental searching.
set incsearch
" Don't use Ex mode, use Q for formatting.
map Q gq
" --- Enable IdeaVim plugins https://jb.gg/ideavim-plugins
" Highlight copied text
Plug 'machakann/vim-highlightedyank'
" Commentary plugin
Plug 'tpope/vim-commentary'
Plug 'tpope/vim-surround'
" using <gr> to do replace from previous yank, instead of "_d or "0p ...
Plug 'vim-scripts/ReplaceWithRegister'
"" -- Map IDE actions to IdeaVim -- https://jb.gg/abva4t
"" Map \r to the Reformat Code action
map <leader>cf <Action>(ShowReformatFileDialog)
map <leader>cF <Action>(ReformatCode)
map <leader>v <C-v>
"" Map <leader>d to start debug
"map <leader>d <Action>(Debug)
"" Map \b to toggle the breakpoint on the current line
"map \b <Action>(ToggleLineBreakpoint)
nnoremap zC :action CollapseRegionRecursively<CR>
nnoremap zO :action ExpandRegionRecursively<CR>
nmap gy :action GotoTypeDeclaration<CR>
" simple spider
" https://stackoverflow.com/questions/71631159/ideavim-move-between-words-in-camel-case-word
map <leader>w [w
map <leader>b [b
map <leader>e ]w
" set bookmark
ideamarks on
" set go to next issue
nnoremap g[ :action GotoPreviousError<CR>
nnoremap g] :action GotoNextError<CR>
Git tips
# only show logs related to main and a branch-a
git lg main..branch-a
# without checking out any branch, push local branch a to b
git push . branc-a:branch-b <-f>
# without checking out any branch, pull/fetch remote to local branch
#(not on main)
git fetch origin main:main
git pull origin main:main
# without checking out branch-top, rebase branch-top onto branch-base
# in the end checking out branch-top (so it still checks out behind the scene)
# assuming main(outdated) ---> branch-a --.--.--> branch-b, and main is outdated, one can do
# (at some branch-b)
git fetch origin main:main
git rebase main branch-a # which will checkout branch-a
# (on branch-a)
git rebase branch-a branch-b <-i> # usually works, if conflicts due to "duplicated" commits, use -i to drop duplicated commits
# (on branch-b now)
# Ends up like: main(updated) ---> branch-a' --.--.--> branch-b'
# And of course the hashes are all changed now for those branches.
Some Markdown Tips
Simply write sub topics here.
Did you know that you can write math equations here like this?
\[ \mu = \frac{1}{N} \sum_{i=0} x_i \]
The Master Method \[ \begin{align} \text{If } \quad T(n) & <= a T (\frac{n}{b}) + O(n^d) \\ \text{Then } \quad T(n) & = \begin{cases} O(n^d \log n) & \quad \text{if } a = b^d \text{ (Case 1)} \\ O(n^d) & \quad \text{if } a < b^d \text{ (Case 2)} \\ O(n^{\log_{b}{a} }) & \quad \text{if } a > b^d \text{ (Case 3)} \end{cases} \end{align} \]
Looks pretty awesome. More info see here
Add a table
|name | length|
|---- |:-----:|
|oarfish| 10m? |
| name | length |
|---|---|
| oarfish | 10m? |
Add a image
You can sort of use github issue page to store some pictures perhaps?

Hidden session
And a hidden session like this to hide a graph:
<details>
<summary>Some hidden stuff here</summary>

</details>
Some hidden code here

Embed an YouTube Video like this:
<iframe width="640" height="360"
src="https://www.youtube.com/embed/WbzNRTTrX0g?t=1557"
frameborder="0" allow="accelerometer; autoplay; clipboard-write;
encrypted-media; gyroscope; picture-in-picture" allowfullscreen>
</iframe>
Mermaid graphs
```mermaid
graph TD
A[Christmas] -->|Get money| B(Go shopping)
B --> C{Let me think}
C -->|One| D[Laptop]
C -->|Two| E[iPhone]
C -->|Three| F[fa:fa-car Car]
```
gives:
graph TD
A[Christmas] -->|Get money| B(Go shopping)
B --> C{Let me think}
C -->|One| D[Laptop]
C -->|Two| E[iPhone]
C -->|Three| F[fa:fa-car Car]
Markdown Notes
Tag <details> for hide or expandable content
<details>
<summary>Summary Goes Here</summary>
...this is hidden, collapsable content...
</details>
which looks like:
Summary Goes Here
...this is hidden, collapsable content...If content inside cannot render as markdown
Try put <details> just after a # title.
(Perhaps just an issue for Spotify techdoc...)
### Just a title can make content inside `<details>` render
<details>
<summary>Click to open</summary>
>>> stuff markdown can render
</details>
Example
Click to open
stuff markdown can render
Nested version
<details><summary> root </summary>
<blockquote>
<details><summary> bin </summary>
<blockquote>
<details><summary> nest1 </summary>
<blockquote>
~~~
a
b
c
~~~
</blockquote>
</details>
<details><summary> nest2 </summary>
<blockquote>
a b c
</blockquote>
</details>
~~~
file1
file2
file3
~~~
</blockquote>
</details>
<details><summary> boot </summary><blockquote>
x y z
</blockquote></details>
</blockquote>
</details>
root
bin
nest1
a b cnest2
a b cfile1 file2 file3boot
x y z
Life tips
Important tips
- Sleep is important, try best to get enough
- Sport is important, daily sprint or long walk helps.
- Do not sit and work hard on something for a long time - 45M break is GOOD
- Do not be influenced by short videos for too long
- Learn some tips on fast reading
- Read more, focus more, plan better
Morning tips
- Most important time is the 1 hour in the morning
- Make bed
- Meditation 10-20m, draw attention back to breath, 7 days will have effect?
- Tune into the peak state -> "I can do it mode"
- code shower?!🤔
- 4:16:8 breath exercise
- short exercise, or a walk outside
- 5 - 10 daily journal
- Peaceful mindset reminding, see below 静心做事法
Evening tips
- Summary daily journal
- old/new relationships that helped you
- an opportunity recently, (call parents, or work)
- something great happened or learned today/yesterday
- something simple
Daily Goal
- Plan entertaining hours, delay gratification
- Try fight with social media / Youtube addiction
- Read more books, write more notes, eat less in the afternoons
- Regular fasting
Daily Productivity Tips
- Keep a todo list and clear it every day before sleep
- Put each day's tasks into their own planning/notes
Weekly Goal
- Write a weekly work summary and note down
- major accomplishment
- perhaps something learned
- perhaps something could be done better, less hurry, or some actions could have been avoided?
耐心,专心,静心
- 禁走险,一误万误
- 禁性猴,事万功一
- 禁无章,仅专万事 得有计划,分主次
静心做事法
一定记住干活说话的时候不要急,要静心细水的来,包括打字😄 这样貌似可以更能集中精力。
- 能
慢下来干事情,这样焦躁感觉会减少很多 - 能
慢下来说事情,别人也能够更好的理解
记得年轻的时候,其实也包括现在,很多情况下还是干事情太急躁,包括打字都想打很快。 给人讲东西说话也快,着急别人理解慢。其实都可以慢下来,平着心去做事,有一种稳妥, 心静的感觉。
感觉这个可以每天早上起来回想一下。
拖延症
- 从低期待开始
- 寻找成就感
- 设定期限
- 远离干扰
- 先搞五分钟再说
不要想着去完成✅ 只看现在这五分钟,半小时能带来的好处 只要今天作出了一点点改进或者进步,明天就会更好一些 不管你面对的事情有多么困难,你有多抵触,多害怕,都不要逃避,因为没人能帮你做。而且往往你只需要迈出那第一步,剩下的第二步、第三步、第四步,都比你想象地要轻松很多
Health tips
- Do more sports
- Vitamin D, K2, potassium and so on are important!
- Listen to Dr. Breg
Happier tips
- When bored, reach out to a good friend, some family menber, or a memtor for a chat.
General tips
- From Daniel EK: pay attention to daily accumulation and compound effect after span of years, value the free time you have before you got kids
- About stock/market: for average people we can perhaps just do long term investment, and buy in/after when you hear big crash news, and sell when your friends/relatives asking you how to open trading accounts.
- You can never really predict the top of the market. If you feel things not correct, the actual change might happen after days or months...
Career Tips
From Mentor Li Ma:
- Pay attention to leardership traning.
- Company scale/document, or maybe follow AWS Leadership Principles. Make sure that you can X on all the requirements or requisites' checkboxes for your next level.
- Asking for help from the right source is also part of a leadership trait.
- Try to be positive and try provide solutions. Complaining won't help you go far.
- Find a mentor (2 or a few levels higher) in another part of the organization, ask for some advices regularly.
- Resume: Focums on impact and key results on the business side. Tech not important.
From Montor Weimin Zhou
- quantify your impact
- quantify your impact
- quantify your impact
- ask a English professional to fix your gramma
- one single line for a bullet point
Human System Optimization
Book Notes Formula
👀 Impressions
💭 This is where I will write down my feelings about the book as I read it
e.g. I found this book life changing...
🪄 Actionable Takeaways
💭 This is a list of the 10 main learning points I took from the book, converted into actionable points - how I can use them in my own life
- e.g. 45 minutes break is going to save you life
- ...
🧝 Fave Quotes
💭These are my favourite literal quotes from the book, that are too well written to summarise, and I might use in my future work
- ...
- ...
🎁 Bonus
💭 Some books have great frameworks for thinking, questions, formulas that I’d like to save - they go here
🌚 Archive
💭 This is where I will store the extra notes and quotes that didn’t make the top 10 cut
Speed Read with the Right Brain (David Butler) / Speed reading (Kam Knight)
Summary of the two books on speed reading.
👀 Impressions
💭 Indeed both book are giving some good tips, but the first one seems more repeating itself, while second one is thinner but gives more tips
🪄 Actionable Takeaways
Book one:
- Read meaningful group of words at a time
- Concentrate on whole ideas instead of words
- Conceptualize the meaning of those ideas
Book two:
- Read in chunks (even staring at spaces between words can work)
- Use visual to conceptualize the meaning of words
- Reduce number of fixations
- Stop sub-vocalization, using humming/music?
- Main sentences, subjects of each paragraph
- Vocabulary (prefixes and suffixes), eye health (rest, massage)
🧝 Fave Quotes
💭These are my favourite literal quotes from the book, that are too well written to summarise, and I might use in my future work
- ...
- ...
🎁 Bonus
💭 Some books have great frameworks for thinking, questions, formulas that I’d like to save - they go here
🌚 Archive
💭 This is where I will store the extra notes and quotes that didn’t make the top 10 cut
Swedish Learning
- People's Dictionary
- Radio Sweden på lätt svenska and click onto the sub session stories to find text.
- Pronunciation
- Swedish Vibe - My Swedish Music List
- SVTplay.se seem like a good place - for example
- Vi ses vi hörs here or here
- https://learningswedish.se/ seems a good place for doing exercise.
Other learning resources
Noun Indefinite/Definite & Plurals Summary
- Swedish Essentials of Grammar - page 82, 90
- Rivstart A1/A2 Övningsbok - page 36
En word type | situation | Singular Definite | Plural Indefinite | Plural Definite |
|---|---|---|---|---|
| en 1 | ends with consonant 辅音 | + en | + ar | + na |
| en 2.a | ends with consonant, but the stress on last vowel | + en | + na | |
| en 2.b | ends with vowel, but the stress on last vowel | + n | + na | |
| en 3 | ends in a | + n | + na | |
| en 4 | ends in e | + n | + na |
Ett word type | situation | Singular Definite | Plural Indefinite | Plural Definite |
|---|---|---|---|---|
| ett 1 | ends with consonant 辅音 | + et | - | + en |
| ett 2 | ends with a vowel | + t | + n | + a |
special general rule: for word end wither, el, en, the unstressedenormally disappears when an ending beginning with a vowel is added.- For example: en åker -> åkren -> åkrar - > åkrarna
| Reason | Singular Indefinite | Singular Definite | Plural Indefinite | Plural Definite |
|---|---|---|---|---|
| en 1 | en bil | bilen | bilar | bilarna |
| en 1 + s | en spegel | spegeln * | speglar | speglarna |
| en 2.a | en kavaj (blazer) | kavajen | kavajer | barnen |
| en 2.b | en kö (queue) | kön | köer | böerna |
| en 3 | en jacka | jackan | jackor | jackorna |
| en 3 | en lampa | lampan | lampor | lamporna |
| ett 1 | ett tält (tent) | tältet | tält | tälten |
| ett 1 | ett barn | barnet | barn | barnen |
| ett 1 + s | ett vapen | vapnet | vapen | vapnen |
| ett 2 | ett linne (背心) | linnet | linnen | linnena |
| ett 2 | ett kvitto | kvittot | kvitton | kvittona |
Verbs
- Swedish Essentials of Grammar - page 64 - 80
- Rivstart A1/A2 Övningsbok - page 75, 75
| word type | IMPERATIVE = BasicForm | INFINITIVE | PRESENT | PAST | SUPINE | Present Participle | Past Participle |
|---|---|---|---|---|---|---|---|
| G2 - Basic ending with consonant | basic | basic + a | basic + er | basic + de; or te after p,t,k,s,x | basic + t | basic + ande | basic + d; or t after p,t,k,s,x |
G1 - Basic ending with a | basic | basic | basic + r | basic + de | basic + t | basic + nde | basic + d |
| G3 - Basic ending with a long stressed vowel | basic | basic | basic + r | basic + dde | basic + tt | basic + ende | basic + dd |
- G4 - special verbs.
- Strong verbs - some "er" verbs are "strong" verbs, they change vowels when in
pastandsupine, and supine ends withit; And for theirpast participle, replaceittoenF.g. Texten är skriven här. (The text is written here.)
| Strong word type | IMPERATIVE = BasicForm | INFINITIVE | PRESENT | PAST | SUPINE | Present Participle | Past Participle |
|---|---|---|---|---|---|---|---|
| skriv | skriva | skriver | skrev | skrivit | skrivande | skriven |
The passive
Adding an s
- If present tense ending in
r, then +rs- öppnar -> öppnas
- If present tense ending in
erthen usually the whole ending disappears- köpper -> köps
- köpper -> köpes (more formal)
Or one can use blev / vara / är + past participle to do the same:
- Bilen blev reparerad, medan vi väntade (The car was repared while we waited)
- Bilen reparerades, medan vi väntade.
- Villan är redan såld. (The house is already sold)
- Villan har redan sålts.
Two Participle from - 两种分词形式
- present participle (presens particip)
- past participle (perfekt particip)
The participles can be used in the same way as adjectives:
- en läsande pojke (present) - a reading boy
- en stängd dörr (past) - a closed door
Examples
| IMPERATIVE = BasicForm | INFINITIVE | PRESENT | PAST | SUPINE | Present Participle | Past Participle |
|---|---|---|---|---|---|---|
| bliv | bli | blir | blev | blivit | blivande | bliven |
| skriv | skriva | skriver | skrev | skrivit | skrivande | skriven |
| stäng | stänga | stänger | stängde | stängt | stängande | stängd |
2022 A1
Info
- Date: 2022-07-04
- Teacher: Louise Gyllengahm louise.gyllengahm@folkuniversitetet.se
- blogg.folkuniversitetet.nu/gylllo - is a link to teacher's blog where she will post homework and class notes after each class.
- Rivstart extramaterial at digital.nok.se - This is a link to the Rivstart extramaterial where you will find wordlists, web exercises etc. Attached in this email is a user manual.
- Link to teacher's personal meeting room at Zoom, if needed.
- SAOL dictionary
- People's Dictionary
Course 1 - 2022-07-04
Arbetar, yrken Occupation
- kock - cook
- läkare - doctor
- lärara - teacher
- adbokat - lawyer
- sjuksköterska - nurse
- ingenjör - engineer
- tandläkare - dentist
- busschaufför - bus driver
- servitör - service guy/lady, waiter
- fotograf - photographer
- frisör - hairdresser
- förskolelärare - preschool teacher
- kemist - chemist
[shemist]
V words
- Vad - what; Vad heter du? / Vad talar du för språk?
- Varifrån - from where; Varifrån kommer du?
- Var - where; Var ligger Umeå?
- Vilket - which; Vilket språk talar du
- Vem - who; Vem vill börja? - Who wants to start?
Basic dialog / Homework K.1/1
- Hej! Jag heter Pia. Vad heter du?
- Juan. Kommer du från Sverige?
- Ja. Och du då?
- Jag kommer från Argentina.
- Jaha. Vad talar du för språk?
- Spanska, svenska, engelska och lite franska.
Homework K.1/2.B
- Nellie kommer från Rumänien.
- Anders förstår lite swahili.
- Petra talar pyttelite kinesiska.
- Oslo ligger i Norge.
Homework K.1/3.B
- Vad heter du?
- Jag heter Fuyang.
- Varifrån kommer du?
- Jag kommer från Kina.
- Vad talar du för språk?
- Jag parta kinesiska, engelska, och pyttelite svenska
- Var ligger Umeå?
- Umeå ligger norra Sverige.
Pronomen: pronoun 代词
- jag du han hon det/den
- vi, ni, de,
[dom]
Course 2 - 2022-07-05
inte - ikke, not; after verb
lätt <> svårt
-
är gift/singel
-
har en fru, man/make, partner, pojkvän, flickvän
-
en katt/hund/ - den katten (that cat, double "en")
-
ett hus/bord - det huset (that house)
Jag har en hund. Hunden heter Iris, men den hunden heter inte Iris.
-
rätt alternativ - the right option
-
vi bor inte ihop
-
Norrköping är en stad (city).
-
Hur länge har ni rarit tillsammans?
-
Vi har varit tillsammans i 5 år
-
Vem vill börja? - who wants to start?
-
Ni är gifta med varandra
Common words
- Förlåt - sorry
- Kanske - maybe
- Lycka till - good luck
- självklart - of course
- det är toppen - great
- lagom är bäst - moderation is best
Course 3 - 2022-07-06
Sjuttiosju skönsjungande sjuksköterskor skötte sju sjösjuka sjömän på skeppet i Shanghai
Seventy-seven singing nurses cared for seven seasick sailors on the ship in Shanghai
Hej och tjena
How are you? 👨
- Hur mår du? (mår -> feel)
- Hur är det?
- Allt väl? (all good?)
- Hur står det till? (står -> stand, formellt)
- Hur är läget? (how is the situation?)
And you? 👩
- Hur mår du själv? / Och själv / Själv då?
I am fine 👍
- Bara bra / det är bra
- Det är lugnt (cool)
- Kanonbra! (great)
- Fint! (great)
- härligt (wonderful)
- Toppen!
- Kanske (maybe)
- det samma (the same)
Not so good... 👎
- Helt okej (fine, completely okay)
Som vanlig(as usual)Så där(so so)- Nja (well well)
- Inte så bra.
- Ganska dåligt faktiskt. (quite bad actually)
- ledsen, jätteledsen (sad)
- jag har huvudvärk (headache)
Tierd:
- trött / jättetröt
- förkyld (cold)
Late:
- jag är sen / försenad
Hungry: hungrig törstig
Often/sometimes
- ofta
- ibland
Random sentences:
- Jag behöver gå till/på toaletten
- Vad gjorde du igår kväll? (What did you do last night?)
- för lätt / för svårt
Good bye:
Tack för idag! Ha en bra dag! Tack detsamma!
Vi ses imorgon! Hej då.
Course 4 - 2022-07-07
Party
- Det är
trevlig/rolig/kuatt träffas.
No problem
- ingen fara
- inga problem
Vad gör du i Sverige?
Fuyang kommer från Kina. Han arbetar på ett mjukvaruföretag. Och han studerar svenska också.
Fuyang bor i lite lägenhen på Tullinge. Hans flickvän bor i Köpenhamn och hon kommer til Stockholm ibland.
Course 5 - 2022-07-08
Question for time/clock
- Vad är klocken?
- Hur mycket är klockan?
When/What time...?
Närbörjar vi?- När vaknar du? / Vanligtris halv tio
Hur dagsäter vi lunch?Vilken tidär det fika?
Course 6 - 2022-07-11
Reflexiva
tvätter sig (wash) / lägger sig (go to bed)
- jag tvättar mig
- du tvättar dig
- han/hon/hen/den/det tvättar sig
- vi - oss
- ni - er
- de - sig
Eftermiddagen
- Eftermiddagen - (in the) afternoon
- Efter middagen - after dinner
- middagen - dinner (old time: lunch...)
Skriv
Klockan halv ätte vaknar jag och stiger upp efter en liten stund (efter väckarklockan ringer flera gånger). Jag dricker ett glas vatten med ett vitaminpiller. Sedan ta jag en dusch och mata min katt.
Klockan ätte dricker jag en kopp kaffe och äter en ägg och kavia buller på ett litet café nerför backen.
Sedan går jag til folkuniversitetet med pendatåg och studerer till 11:15.
Vid tolv äter jag lunch på en liten restaurang i stan. Sedan arbetar jag till eftermiddagen.
När jag kommer hem efter 7:00, tittar jag på Netflix. Jag går och lägger mig vid 11:30 och somnar direct :)
Course 7 - 2022-07-12
| Imperative | Infinitive | Pressens |
|---|---|---|
| bo | bo | bor |
| jobba! | jobba | jobbar |
| ät | äta | äter |
| kom | komma | kommer |
| sov | sova | sover |
| drick | dricka | dricker |
| läs | läsa | läser |
| skriv | skriva | skriver |
| köp | köpa | köper |
| titta | titta | tittar |
Must/have to
- bör - should
- behöver - have to
- måste - must
Course 8 - 2022-07-13
Mat
Vad är din favoritmat? Du ska laga din favorifma. Vad behöver du? Skriv en lista:
Frukostbröd med ägg och kaviar
- Cut the bread in half (not all through)
- spread some "Kalles original"
- put a cabbage in
- slice a boiled egg and put it on the cabbage
- add some green stuff like small piece of peper
- put "small bean sprout" on it the egg
- Done. Enjoy it :)
Course 9 - 2022-07-14
Idag ska jag plugga svenska på Folkuniversitetet. Vi ska parta om aktiviteter.
Efter kursen ska jag äta lunch - en stor portion sallad - på ett kafé som heter "Bröd & Salt" nära skolan.
På eftermiddage ska jag arbeta. Efter det planterar jag för att shoppa några "happy socks".
Ikväll ska jag göra mina läxor och gå ut med min katt efter det.
Imorgon på fredag ska jag studera svenska igen och efter det ska jag gå på yogakurs med Yan och det ska bli roligt :)
Course 10 - 2022-07-15
Skriv fyra saker du gillar at göra
- Jag tycker om att fotografera
- Jag älskar att gå i skogen och skjuta pilbåge och plocka svamp.
- Jag grillar att spela fotball, badminton och simning.
Course 11 - 2022-07-18
Släktträd
- Fuyang
far/pappaChangzheng LiufarfarGuangtian LiufarmorSixuan WangfarbrorChangKai LiukusinJiaqi
fasterB LiukusinZhao Zhao
morShuping SunmormorYuhua RenmorfarYutai SunmorbrorPeng SunkusinerCarylin, Nana
mosterShujuan, MinkusinerYue, Zhengxin
Course 12 - 2022-07-19
time
i tisdags- last Tuesday- i somras
- i vintras
- i våras - last spring
- i höstas - last fall
- Vad gjorde du i tisdags?
på tisdag- this Tursdayi sommar- this summer- Vad ska du göra på tisdag?
sommar
i sommar- this summeri sommras- last summer
Jag har en mamma som heter Shuping. Hon jobbade som HR chef på ett lokalt byggföretag. Men nu är hon och min pappa pensionerade.
Min pappa heter Changzheng och han var chaufför när han var ung. När jag var liten kände jag att hans lastbil var superkraftig.
Min pappa har en syster som bor i Tyskland och arbetade som en tekniker. Och min mamma har en bror som bor i California och arbetar som en chef inom chipindustrin.
Men jag bor och arbetar i Sverige nu. Min flickvän och jag har två katter som heter Hugo och Hector. Våra katter bråkar ibland med varandra.
Course 14 - 2022-07-21
Homework: page 82, 90 gramma book summary
- S: Kan jag hjälpa dig?
- B: Jag behover ett nytt par skor. jag vill ha jump skor.
- S: Jo, då har vi de här bäst kvalitet jump skor. Vill du prova?
- B: Ja gärna, jag har storlek 38
- S: Vilken färg vill du prova? Den här?
- B: jag skulle vilja prova de vita skorna
- S: Varsågod. Passar de bra?
- B: nej, de är för små. Har du en större storlek?
- S: Självklart, en sekund , ett ögonblick... Varsågod, de er storlek 39.
- B: ja, de är lagom
Course 15 - 2022-07-22
e, i y, ä, ö change sounds of g, k, h
- g -> [j] Gösta
- k -> [sch] Kina, kön (gender)
- sk -> [h] Kanske
Special, undantag
- kön - [kön] the queue/line, kö (queue)
- kön - [tjö:n] / [shö:n] gender
Vi gör vårt bästa
Course 16 - 2022-07-25
- Vad gjorde du i helgen?
- Jeg stannade hemma och tittade på Youtube hela dagen.
- sammanfattning av svensk grammatik
Course 17 - 2022-07-26
hem- destination- Jag måste går hem
hemma- position- Jag är hemma
- Jag bor hemma hos mamma
Transporter - transportation
gå- people "walk". Man går med fötterna = Promenerar.
- tåget/färjan "leave"
åka- people go somewhere with car/train/boat...- Man åker bil, buss, tunnelbana, tåg, helikopter, flyg o.s.v.
some words
- Ett ögonblick. (One moment, one eye blink)
- Det beror lite på trafiken. (It depends on...)
Course 18 2022-07-27
Tidsprepositioner:
- Framtid (future):
omas in English "... in "- Bussen går
omfem minuter - Kursen slutar om tre dager
- Bussen går
- Dåtid:
för+seden- as in English "for"- Jag såg utställningen
fören veckaseden.- (I saw the exhibition one week ago )
- Jag såg utställningen
Course 19 - 2022-07-28
方位介词 position preposition
under(under)mellan(between)bredvid(next to/at)- Katten är bredvid lådan.
i(in)över(over)ovanför(above, similar with över)- Lampan hänger ovanför bordet. (The lamp hangs above the table.)
bakom(behind)på(on)framför(in front of)
Other:
från(from)ur(out)- Ta handen ur fickan. (Take your hand out of your pocket)
med(with)vid(at/by)- Hon sitter vid fönstret. (She is sitting by the window)
till(to)hos(at, be with)- Han var hos läkaren. (He is at the doctor.)
i vs på
i+ stad(stad)/land/region/landskap/park/affären(store)/rummet/husetpå+ gata/torg(square)/öpå+ plaster med specifik aktivitet (restaurang, kafé, bio, teater, jobbet, sjukhuset, ICA)
| i | på |
|---|---|
| i huset | på biblioteket |
| i affären | på bio |
| i kiosken | på torget |
| i kyrkan | på hotel |
| i skolan (study, 上学) | på skolan (work or being there) |
| i fängelset | på sfi-kurs |
| i parken | på kafe |
| i veckan (a week) | på bussen |
| i vardagsrummet (in the living room / rummet/huset) |
- Jindra är i skolan. (Jindra goes to the school)
- Louise jobbar på skolan. (Work at the school)
Grattis / Gratis
Course 20 - 2022-07-29
- tak som frågar (thanks for asking)
2022 A2
https://blogg.folkuniversitetet.nu/hackfe/svenska-a2-augusti-2022/
Course 01 - 2022-08-01
- Jag flyttade til Stockholm
förtre år sedan. - Ta en promenad.
- Brukar du göra det? (Do you used to do that?)
Kör
- Jag kör bil ([shör])
- sjunger i kör ([kör])
Också | Inte heller
Following a normal statement
- Jag tycker om blodpudding.
- ✅ (agree) Jag också. | ❌ (disagree) Det gör inte jag.
Following a inte statement
- Jag tycker
inteom blodpudding. - ✅ (agree) Inte jag heller. | ❌ (disagree) Men det gör jag.
Homework page 103
- Utställningen var inte så intressant så efter en kvart gick jag hem.
- Den här veckan har jag mycket att göra men nästa vecka kan jag hjälpa dig.
- Nu går jag hem för jag mår inte så bra.
- Jag måste plugga nu och sedan (later) ska jag gå ut med hunden.
- Idag är jag pigg men igår var jag jättetrött.
- Annika läser tidningen och Rolf tittar på teve.
- Kan du handla mat eller ska jag göra det?
- I fredags träffade jag mormor och nästa vecka ska jag träffa farfar.
- Tyvärr kan jag inte gå ut ikväll för jag har inga pengar.
- Klockan är åtta så nu måste vi gå.
Course 02 - 2022-08-02
Course 03 - 2022-08-03
- jag triver mig bra i Sverige
- jag känner mig bra i Sverige
Course 04 - 2022-08-04
- Vad är skillnaden (diff) mellan A och B?
- Skillnaden mellan A och B är ...
tror vs. tycker
- tror - vet inte, är inte säker (sure)
- tycker - har en åsikt(opinion)/värdering(valuation)
Course 06 - 2022-08-08
- Vad handlar filmen om?
- Filmen handlar om em projekt om batteri.
Course 07 - 2022-08-09
- Han serverade kaffe och te till passagerarna på flygplanet
- Stiger av = kliver av = går av
- sätta på = öppnade
- stänga av = deaktivera
Course 08 - 2022-08-10
TV Show - Huss
Säsong 1 - Avsnitt 1
Words
- avfyra - fire
- hända - happen
- stenar, gatstena - stones, rocks
- vilka - which
- oklart - unclear, hard to grasp
- vi skulle hälla våra positioner. inte släppa förbi demonstranterna. - we would hold our positions. do not let the protesters pass.
- de kom närmare och närmare - they came closer and closer
- mer stenar, flaskor, all möjlig skit - more rocks, bottles, all sorts of crap
- fick ni nåt stöd internt efteråt - did you receive any support internally afterwards
- prata - talk
- med varann - to each other
- du har inga såna tankar - you have no such thoughts?
- nog - enough / probably
- lägga (lagt) - put
- det hela - all of it
- värst - worst
- Det viktigaste är att vi håller ihop - the most important is we stick together
- gäller - matter, it is important to
- ha koll på - keep check of, be aware of
- var ert befäl är - where your commander is
- tänk på - consider, think of, remember,
- här - here
- lycker till - good luck
- lägg av - stop / leave off
- Släpp - let go
- Lugna ner dig
- Gör some jag säger, sätt dig - Do as I say, sit down
- Gå ditåt - go that way
- honom - him
- nånstans - anywhere, somewhere
- det räcker! - it is enough!
- vänd dig om - turn around
- käften - shut up
- tyvärr - unfortunately
Cheese study
Score from 0 to 5.

Score: 5

Score: 4, stronger than the one above.

Score: TODO
Restaurants in Stockholm
Asian Style
Xiang Yue
- Friendly family style restaurants.
- Price: low/mid
- Score: 4.8 / 5
Jappi
- Where you can try 羊肉泡馍
- Price: mid
- Score 4.5 / 5
Sibiriens Sinokök - Roslagsgatan 25
- Chinese restaurants with a weird name?
- Price:
- Score:
To be tested
Koreana Restaurant - Luntmakargatan 76
- Only if you like code bibimbap...
- Price: low
- Score: 3.8 / 5
An Nam - Tegnérgatan 19
- Vietnamese restaurants
- Price: mid
- Score: 4 / 5
Pho seems okay nothing too special. Need to try other dishes.
Rawbata - Rörstrandsgatan 15
- Japanese BBQ ramen
- Price: mid/high
- Score: 3.5 / 5
Only tried ramen sometime ago, just so so. Perhaps should try something else next time.
Other Style
Aifur - Västerlånggatan 68b
- Old town Viking style
- Price: high
- Score: 4.5 / 5
Good honey beer and meat, good music and atmosphere.
Tehran Gril - Rörstrandsgatan 15
- Persian / middle east style
- Price: mid
- Score: 4 / 5
Grilled fish seems quite nice
Hot little India - Sveavägen 96
- Indian restaurants
- Price: mid
- Score: 4 / 5
Rawbata - Rörstrandsgatan 15
- Japanese BBQ ramen
- Price: mid/high
- Score: 3.5 / 5
Only tried ramen sometime ago, just so so. Perhaps should try something else next time.
Seems quite large portion.
About learning and memory
Imagine helps memorization?
好像小时候学生物课的时候很多知识点还记得不错, 很可能是靠一些视觉化的想象力,比如去想象细胞内部结构之间的物质交换
物理有时候感觉也理解的还不错,也可能是因为经常去想象一个物体比如 其受力情况,速度,加速度等等。解体的时候有很多想象,有一种能“看到“ 并且”感悟“到物体运作方式的感觉。
现在搞搞程序,计算机编程,好像一直还没有尝试去把系统组件物像化, 把系统之间信息的格式和流动都视觉化出来,很有可能能帮助我记忆和理解 计算机系统以至于算法和数据结构。
但可能在用此方法尝试记忆或者理解算法的时候,需要很大的”working memory“ 或者说“工作记忆”1^ - 也就是说那种,比如在下象棋时候需要的, 能够在大脑中记住并呈现出来物件的状态,并能持续想象随着时间的发展,此物件 状态的持续变化也能在大脑当中清晰的展现和保存。
记得我小时候,尝试学下象棋的时候,总是感觉记不住棋盘 两三步之后的状态。估计没有太多天赋在这上面吧哈哈。不过还好 我们干活的时候还可以打草稿,没必要全在脑子里展现。
不过以后我决定多训练训练视觉的想象,然后看能否用来把知识 视觉化以便加强记忆。