Hollow Example (with Ktor)
The problem
Software engineers often encounter problems which require propagating of small or moderately sized data sets which don’t fit the label “big data”.
Suppose a usage case like this:
- We have a list of some InfoEntity, such a list of Messages or whatever information entity that is updated on a single service (master/producer), but this list of data is required on multiple other services (followers/consumers) to do their own job
- This list of entities is not very large
- All followers/consumers would like to access the elements of this list very frequently.
- All followers/consumers would like to have the minimum latency when accessing this data, while geologically the followers are very far away from the producer.
To solve these problems, we often send the data to an RDBMS or nosql data store and query it at runtime. But there are limitations on the latency and frequency with which you can interact with that dataset.
Or we could serialize the data as json or xml, distribute it, and keep a local copy on each consumer. But serializing and keeping a local copy (if in RAM) can allow many orders of magnitude lower latency and higher frequency access, but this approach has many scaling challenges:
- The dataset size is limited by available RAM.
- The full dataset may need to be re-downloaded each time it is updated.
- Updating the dataset may require significant CPU resources or impact GC behavior.
The solution
Netflix Hollow is a java library and toolset for disseminating in-memory datasets from a single producer to many consumers for high performance read-only access. Hollow aggressively addresses the scaling challenges of in-memory datasets, and is built with servers busily serving requests at or near maximum capacity in mind.
Hollow simultaneously targets three goals:
- Maximum development agility
- Highly optimized performance and resource management
- Extreme stability and reliability
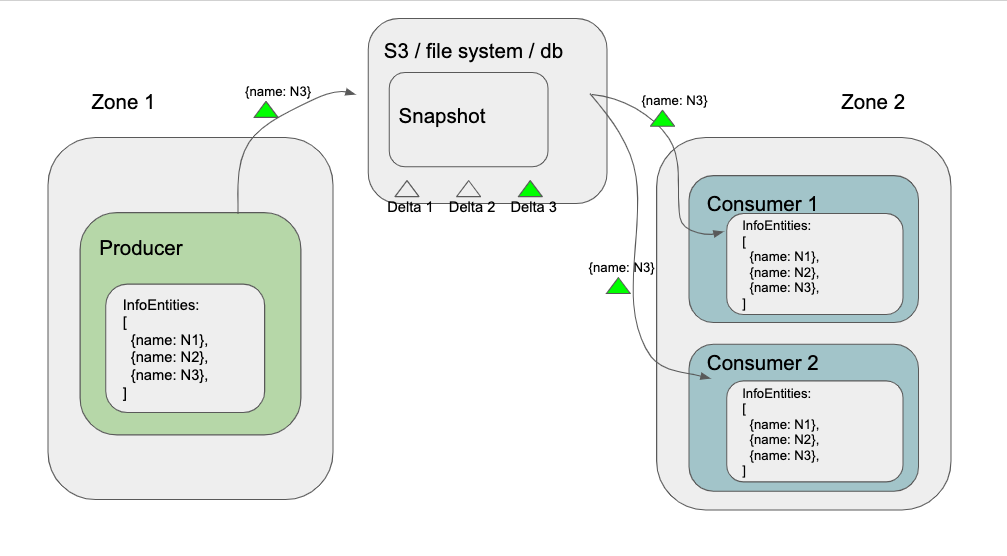
Basically, you can view Hollow as a distributed system framework that can allow you to propagate data from a single producer’s memory to multiple followers’ memory (read only).
The performance optimization is largely contributed by the mechanism of using Snapshot and applying Difference while propagating changes to flowers.
Over time, Hollow automatically calculates the changes in a dataset on the producer. Instead of retransmitting the entire snapshot of the data for each update, only the changes are disseminated to consumers to keep them up to date.
On consumers, Hollow keeps a compact encoding of the dataset in RAM. This representation is optimized for both minimizing heap footprint and minimizing access CPU cost. To retain and keep the dataset updated, Hollow pools and reuses heap memory to avoid GC tenuring.
Sounds good, so let’s try it?
In this post we give Hollow a try. You can see all the source code in this post from this repo: github.com/liufuyang/hollow-example-ktor.
Hollow does have an example repo at here. However it is not using any web services to help understand how to use it in our cases. That’s the reason that why I wrote this post to show you from another angle how to integrate Hollow in your web servers.
To help make the code simple, I used Kotlin and Kotlin’s web framework Ktor. As Kotlin code and Java code can be transformed to each other without difficulty, you can still follow this guide if your services are in Java only.
We will firstly create a simple Ktor web service as a producer. In it’s memory we keep a
map of data called db: Map<Int, InfoEntity>. To make code simple we will just use a
not thread safe version of the map and add some simple endpoint to show and update this map, as if it is some kind of database.
Then later on we show how to use Hollow to propagate this db data onto another running
service - a consumer.
For the simplicity, we will just use a local file location target/publish in the producer project
folder for Hollow to publish Snapshot and Deltas. For production cases you probably want to use
a database system and a AWS S3 to do that. It is fairly easy to set it up.
See more info at Hollow’s quick start pages.
For now, we can start with some coding to firstly create a webserver.
Step 1 - Make a simple Ktor service
We start with making a service as a producer. The code is in folder
hollow-ktor-producer.
With https://ktor.io/quickstart/generator.html# you can simply generate a Ktor project.
Otherwise you are welcome to use the code I have for this blog post at https://github.com/liufuyang/hollow-example-ktor
Firstly when you create a Ktor project, in the main file you will see something like these:
routing {
get("/") {
call.respondText("HELLO WORLD!", contentType = ContentType.Text.Plain)
}
get("/json/gson") {
call.respond(mapOf("hello" to "world"))
}
}
And know you can start the server and do query on it via curl or browser, you can get text return or a json return.
Hold an object in memory
Now we add some extra code to the empty server code. We firstly
create a data class InfoEntity annotated with @HollowPrimaryKey(fields=["id"]).
So that Hollow will know we would like to use this class as
data entity class, also using the field id as it’s primary key.
Hollow will not allow duplicate primary keys when store entity class
data in memory.
Then we add the code to create a memory db to hold a list of
those InfoEntitys (each one has an unique id).
This is not thread safe but we keep it simple for illustration of Hollow usage.
package com.example
import com.netflix.hollow.core.write.objectmapper.HollowPrimaryKey
@HollowPrimaryKey(fields=["id"])
data class InfoEntity(
val id: Int,
val name: String,
val status: String,
val timeUpdated: Long
)
...
fun Application.module(testing: Boolean = false) {
install(ContentNegotiation) {
gson {
}
}
val db = mapOf(
1 to InfoEntity(1, "News 1", Status.NEW, 0),
2 to InfoEntity(2, "News 2", Status.NEW, 1),
3 to InfoEntity(3, "News 3", Status.NEW, 2)
).toMutableMap()
routing {
get("/info") {
call.respond(db.values)
}
post("/info") {
val newInfo = call.receive<InfoEntity>()
println(newInfo)
db[newInfo.id] = newInfo
producer.runIncrementalCycle { state ->
state.addOrModify(newInfo)
}
call.respond(HttpStatusCode.Created)
}
}
}
Here in post("/info") we store new data entry into the db,
whose elements have unique ids as if it is some database system.
Now you can verify the producer endpoint to check all the values in db:
curl localhost:8080/info
[
{
"id": 1,
"name": "News 1",
"status": "NEW",
"timeUpdated": 0
},
...
]
Or you can use the endpoint like this to add/update a certain value in db:
curl -i -X POST localhost:8080/info -H "Content-Type: application/json" -d '{"id":4, "name":"A new item", "status":"NEW", "timeUpdated":3}'
curl localhost:8080/info
[
{
"id": 1,
"name": "News 1",
"status": "NEW",
"timeUpdated": 0
},
...
{
"id": 4,
"name": "A new item",
"status": "NEW",
"timeUpdated": 3
}
]
Step 2 - Make service as a Hollow Producer
We’ll need a data producer to create a data state which will be transmitted to consumers.
// producer code
...
fun Application.module(testing: Boolean = false) {
... // same code above, neglected
val db = mapOf(
1 to InfoEntity(1, "News 1", Status.NEW, 0),
2 to InfoEntity(2, "News 2", Status.NEW, 1),
3 to InfoEntity(3, "News 3", Status.NEW, 2)
).toMutableMap()
/** Hollow setup **/
val localPublishDir = File("target/publish")
val publisher = HollowFilesystemPublisher(localPublishDir.toPath())
val announcer = HollowFilesystemAnnouncer(localPublishDir.toPath())
val producer = HollowProducer
.withPublisher(publisher)
.withAnnouncer(announcer)
.buildIncremental()
producer.runIncrementalCycle { state ->
for (e in db.values)
state.addIfAbsent(e)
}
/** End of Hollow setup **/
routing {
... // same code above, neglected
}
}
Noticing here we use state.addOrModify(newInfo) instead of state.addIfAbsent(newInfo)
so that we can also use this endpoint to update on an already existing entity.
Step 3 - Create a consumer that reconstruct entities in memory
Generate Hollow source code (Hollow API) for consumer to use
Before we move on to build our consumer, we first need to let Hollow generate some source code (the so-called Hollow API) that can be used for our consumer later.
It is very simple to generate these code, simply make a main function like the code below and run it directly via ide, then the API code will be generated:
// GenerateHollowSource.kt
import com.netflix.hollow.api.codegen.HollowAPIGenerator
import com.netflix.hollow.core.write.objectmapper.HollowObjectMapper
import com.netflix.hollow.core.write.HollowWriteStateEngine
fun main() {
val writeEngine = HollowWriteStateEngine()
val mapper = HollowObjectMapper(writeEngine)
mapper.initializeTypeState(InfoEntity::class.java)
val generator = HollowAPIGenerator.Builder().withAPIClassname("InfoEntityAPI")
.withPackageName("com.example.hollow.generated")
.withDataModel(writeEngine)
.build()
generator.generateFiles("../hollow-ktor-consumer/src/")
}
The only thing worth noticing is that the generatedFiles is set to ../hollow-ktor-consumer/src/,
as my producer and consumer project is side by side so I can generate the
code directly into the consumer project, saving me some time to copy
files around.
After running the main function above, you should see those Java files are generated in consumer project:
Another super good thing of Kotlin I have to mention is that you can use Kotlin together with Java code in the same project. So even Hollow generated only Java files, we don’t have to do anything else, we can directly use them in our Kotlin consumer project :)
Writing consumer code
How we can add some code for our consumer. The consumer code exist in
another project folder hollow-ktor-consumer
// consumer code
...
fun Application.module(testing: Boolean = false) {
install(ContentNegotiation) {
gson {
registerTypeAdapter(InfoEntity::class.java, InfoEntityAdapter())
}
}
/** Hollow setup **/
val localPublishDir = File("../hollow-ktor-producer/target/publish")
val blobRetriever = HollowFilesystemBlobRetriever(localPublishDir.toPath())
val announcementWatcher = HollowFilesystemAnnouncementWatcher(localPublishDir.toPath())
val consumer = HollowConsumer.withBlobRetriever(blobRetriever)
.withAnnouncementWatcher(announcementWatcher)
.withGeneratedAPIClass(InfoEntityAPI::class.java)
.build()
consumer.triggerRefresh()
/** End of Hollow setup **/
routing {
get("/info") {
val infoEntityAPI = consumer.getAPI() as InfoEntityAPI
call.respond(infoEntityAPI.getAllInfoEntity().stream().collect(Collectors.toList()))
}
}
}
You would also need a InfoEntityAdapter on the consumer side to help gson turn the
Hollow generated InfoEntity into Json format.
import com.example.hollow.generated.InfoEntity
import com.google.gson.JsonElement
import com.google.gson.JsonObject
import com.google.gson.JsonSerializationContext
import com.google.gson.JsonSerializer
import java.lang.reflect.Type
class InfoEntityAdapter : JsonSerializer<InfoEntity> {
override fun serialize(
src: InfoEntity, typeOfSrc: Type,
context: JsonSerializationContext
): JsonElement {
val obj = JsonObject()
obj.addProperty("id", src.id)
obj.addProperty("name", src.name.value)
obj.addProperty("status", src.status.value)
obj.addProperty("timeUpdated", src.timeUpdated)
return obj
}
}
Now you can play with the producer and consumer simply via the /info endpoint:
# Firstly verify the initial data get populated to consumer side:
curl localhost:8081/info | jq .
# Then add one element from the producer side:
curl -i localhost:8080/info -H "Content-Type: application/json" -X POST -d '{"id": 4, "name": "News 4", "status": "NEW"}'
# Then verify again the data get updated on the consumer side:
curl localhost:8081/info | jq .
The output is neglected above.
Using an UniqueIndex
So far we can get data propagated to the consumer side. But we
only used the infoEntityAPI.getAllInfoEntity() call to get all
the element in the list memory. This will be very inefficient
especially when you have a long list with big entities propagated
in the consumer side memory.
In order to fetch a single element out from the list efficiently,
a common way to do is to use the element id as a unique index to
query the element out from the Hollow memory. Remember the
element id is defined as a Hollow index primary key by annotation
@HollowPrimaryKey(fields=["id"])
Hollow provide a uniqueIndex method that allows you to do this.
We can try it out as follow:
// consumer code - Application.kt
...
/** Hollow setup **/
...
// Setting up an id index
val uniqueIndex = InfoEntity.uniqueIndex(consumer)
consumer.addRefreshListener(uniqueIndex)
...
/** End of Hollow setup **/
In the /** Hollow setup **/ session, we can create
an uniqueIndex from the consumer.
Noticing that the call consumer.addRefreshListener(uniqueIndex)
is important. If you miss this line, even the consumer itself
can still update while new version data is published, but the
index will be staying unchanged, making it will not find the
newly added elements.
After we create index as above, we can use it via a newly added get endpoint as follow:
// consumer code
get("/info/{id}") {
val id = call.parameters["id"]?.toInt() ?: throw IllegalStateException("Must provide id")
val infoEntity = uniqueIndex.findMatch(id)
if (infoEntity != null) {
return@get call.respond(infoEntity)
} else {
return@get call.respond(HttpStatusCode.NoContent)
}
}
Now we can test it on the consumer side as:
curl localhost:8081/info/4 | jq .
{
"id": 4,
"name": "News 4",
"status": "NEW",
"timeUpdated": 0
}
Using a HashIndex
Above index give you the ability to select a single element via
@HollowPrimaryKey(fields=["id"]). What if you want to select
multiple elements with a field’s value equal to some value?
This can be achieved by using a HashIndex.
Suppose we would like to use the name field to select all the
InfoEntity that have the same name, we can do something like this:
Add it like this:
// consumer code - Application.kt
...
/** Hollow setup **/
...
// Setting up an Hash Index
val builder = HashIndex.from(consumer, InfoEntity::class.java!!)
val nameIndex = builder.usingPath("name.value", String::class.java)
consumer.addRefreshListener(nameIndex)
...
/** End of Hollow setup **/
Plus another endpoint to use nameIndex:
get("/info/name/{name}") {
val name = call.parameters["name"] ?: throw IllegalStateException("Must provide name")
val infoEntities = nameIndex.findMatches(name).collect(Collectors.toList())
if (infoEntities.isNotEmpty()) {
return@get call.respond(infoEntities)
} else {
return@get call.respond(HttpStatusCode.NoContent)
}
}
Now we can play it again with adding two element with firstly adding entities of the same name, then use the newly added endpoint to select them:
curl -i localhost:8080/info -H "Content-Type: application/json" -X POST -d '{"id": 4, "name": "News 4", "status": "NEW"}'
curl -i localhost:8080/info -H "Content-Type: application/json" -X POST -d '{"id": 5, "name": "News 4", "status": "NEW"}'
curl localhost:8081/info/name/News%204 | jq .
Now we get all the element with name="News 4"
HashIndex with Enums
Above we can see the HashIndex can be build via builder.usingPath("name.value", String::class.java), where the name field is a String value. What if the index
field is not a String type but some Enum type?
Then you cannot use the path as name.value, but you can use enum._name.
Here I have an example for you. Firstly let’s change the Producer side’s
InfoEntity definition to introduce an Enum.
# producer code - InfoEntity.kt
import com.netflix.hollow.core.write.objectmapper.HollowPrimaryKey
@HollowPrimaryKey(fields=["id"])
data class InfoEntity(
val id: Int,
val name: String,
val status: Status,
val timeUpdated: Long
)
enum class Status {
NEW, OLD
}
Then run the main function of GenerateHollowSource.kt to generate the updated
source code API for the consumer side.
Then update the consumer code as follow:
// consumer side - InfoEntityAdapter.kt
obj.addProperty("status", src.status._name)
Then add the HashIndex on this Enum Status:
- Application.kt
...
// Setting up an Hash Index on Enum
val statusIndex: HashIndex<InfoEntity, String> = builder.usingPath("status._name", String::class.java)
consumer.addRefreshListener(statusIndex)
...
Lastly add another endpoint to test it:
// consumer side - Application.kt
get("/info/status/{status}") {
val status = call.parameters["status"] ?: throw IllegalStateException("Must provide status")
val infoEntities = statusIndex.findMatches(status).collect(Collectors.toList())
if (infoEntities.isNotEmpty()) {
return@get call.respond(infoEntities)
} else {
return@get call.respond(HttpStatusCode.NoContent)
}
}
And again, now you can verify the HashIndex works on Enum as well:
curl -i localhost:8080/info -H "Content-Type: application/json" -X POST -d '{"id": 4, "name": "News 4", "status": "OLD"}'
curl -i localhost:8080/info -H "Content-Type: application/json" -X POST -d '{"id": 5, "name": "News 4", "status": "OLD"}'
curl localhost:8081/info/status/OLD | jq .
Restoring Producer at Startup
So far our producer-consumer Hollow system seems working find. But there is
actually still a big problem remains. If you have monitored the publish file
location, target/publish in our example’s case, you will notice that
each time you start the producer, a new Snapshot is created.
This could be a problem in the way that
- Firstly it making the old snapshot not used anymore, and creating a new snapshot on each producer restart
- Secondly when a new state with only a snapshot will be produced and announced, and clients will load that data state with an operation called a double snapshot, which has potentially undesirable performance characteristics.
More discussion of this can be seen here.
We can remedy this situation by restoring our newly created producer with the last announced data state. For example, change the producer code to this:
// producer code - Application.kt
...
/** Hollow setup **/
val localPublishDir = File("target/publish")
val publisher = HollowFilesystemPublisher(localPublishDir.toPath())
val announcer = HollowFilesystemAnnouncer(localPublishDir.toPath())
val blobRetriever = HollowFilesystemBlobRetriever(localPublishDir.toPath())
val announcementWatcher = HollowFilesystemAnnouncementWatcher(localPublishDir.toPath())
val producer = HollowProducer
.withPublisher(publisher)
.withAnnouncer(announcer)
.buildIncremental()
producer.initializeDataModel(InfoEntity::class.java)
val latestAnnouncedVersion = announcementWatcher.getLatestVersion()
producer.restore(latestAnnouncedVersion, blobRetriever)
producer.runIncrementalCycle { state ->
for (e in db.values)
state.addIfAbsent(e)
}
/** End of Hollow setup **/
...
Now we add a blobRetriever and a announcementWatcher which was used previously
only for consumer. By calling producer.restore(latestAnnouncedVersion, blobRetriever)
now we can reuse the previously announced Snapshots while service starts.
Here we assume the data is going to be loaded into the producer service is not changed
while service is down. That’s why we can use state.addIfAbsent(e) in the
producer.runIncrementalCycle {...} block.
If in other cases we can’t guarantee that, or meaning that when producer is restarting,
the data to be loaded into it, is already different from the Hollow snapshots
previously published, you might want to switch that function call to
state.addOrModify(e) so that the updated element info can be registered into
Hollow state and get published or announced as well later on.
Summary
Hopefully now you can see how easy it is to use Hollow to propagate data into other services’ memory. Please comment below if you have more questions or any suggestions to help me improve this post. Thank you for reading so far.