Let's play with TiDB + TiSpark - Part 1 - Running in docker
Last week I heard about Ti-DB, it seems to be a very interesting distributed DB solution.
Ti-DB, according to their Github definition, is an open-source distributed scalable Hybrid Transactional and Analytical Processing (HTAP) database. It features infinite horizontal scalability, strong consistency, and high availability. TiDB is MySQL compatible and serves as a one-stop data warehouse for both OLTP (Online Transactional Processing) and OLAP (Online Analytical Processing) workloads.
“No more ETL” as they acclaim.
It sounds good. And according to this there are many companies already using Ti-DB in production. Whether it is that powerful or not, I can’t really say much here. But I plan to play around with it anyway.
To get more informations about it, they have a Github.io blog which is really informational: https://pingcap.github.io/blog/
[Step 1] - Spin up TiDB+TiSpark in docker in 5 minutes
There is a very nice blog from TiDB already on how to do this: https://pingcap.github.io/blog/how_to_spin_up_an_htap_database_in_5_minutes_with_tidb_tispark/
You can follow it there for the most of the steps, then check the Step 2 here for using TiSpark with a Jupyter Notebook.
And TiDB team has made a repo asically speaking, you only need to a few lines of command to spin everything up:
git clone https://github.com/pingcap/tidb-docker-compose
cd tidb-docker-compose
docker-compose up -d
To check if your deployment is successful:
* docker ps or docker stats
* Go to: http://localhost:3000 to launch Grafana with default user/password: admin/admin.
* Go to TiDB-vision at http://localhost:8010 (TiDB-vision is a cluster visualization tool to see data transfer and load-balancing inside your cluster).
To connect onto the database with your favourite MySQL client:
mysql -h 127.0.0.1 -P 4000 -u root --default-character-set=utf8
If seeing errors like ERROR 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 0
then try change the host to 0.0.0.0. It might be some glitch
To inject some test data into the db (using the data file already packed inside Ti-Spark’s image)
docker-compose exec tispark-master bash
cd /opt/spark/data/tispark-sample-data
mysql -h tidb -P 4000 -u root < dss.ddl
Now you should be able to see the data under database TPCH_001 from your favourite MySQL client.
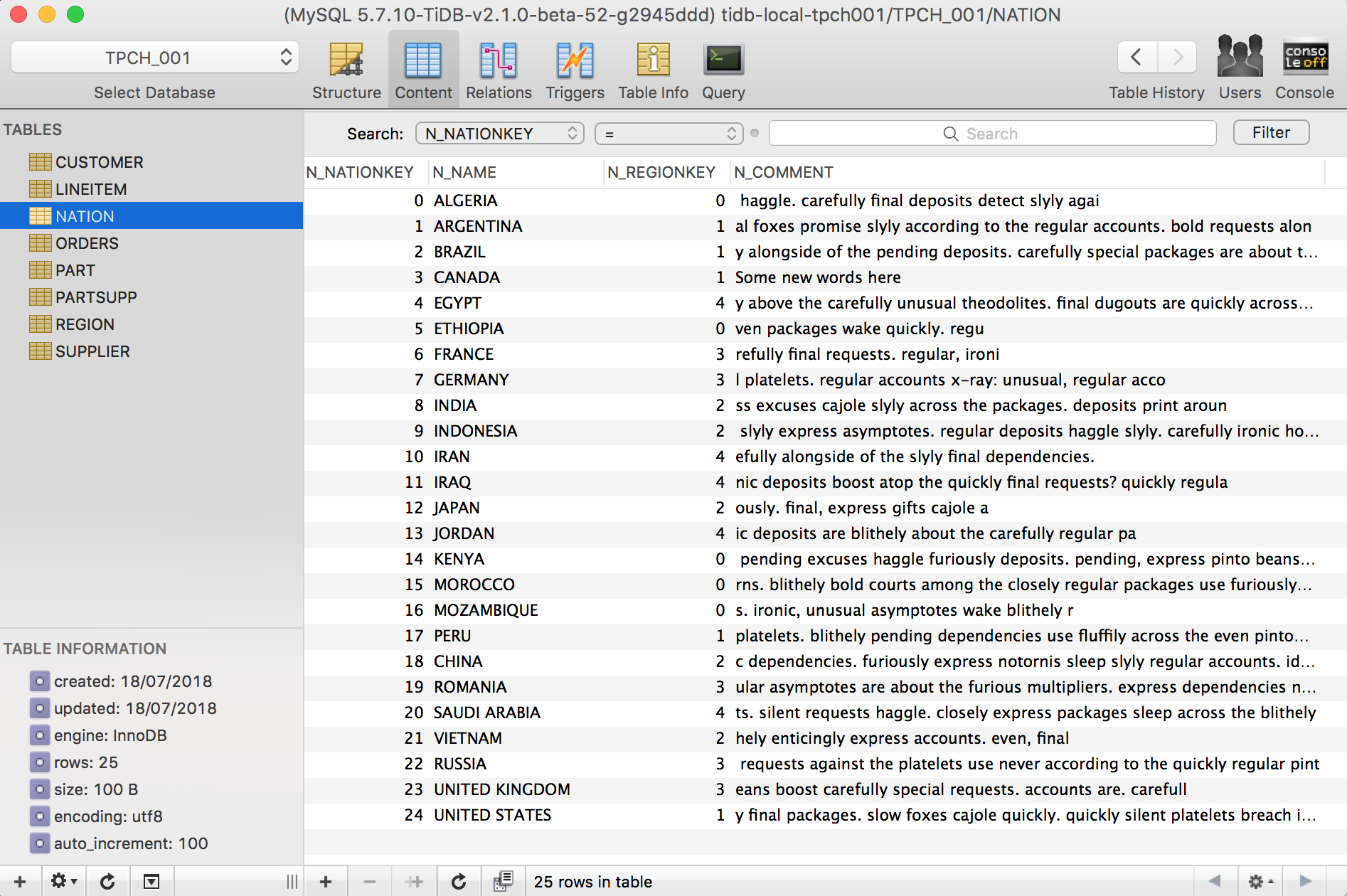
[Step 2] - Connect the TiSpark master with a Ipython Notebook
I have made a docker image that can start a container that has an Ipython Notebook also it can wires up with the TiDB cluster you just created by the command above. More info you can see here and here
So while your TiDB cluster is running in docker, start notebook like this:
git clone https://github.com/liufuyang/tidb-learning
cd tidb-learning
docker-compose up
Firstly you can check on localhost:8080 for the Spark Master info. You can see the number of Spark workers you have.
Then visit localhost:8888 and login with the token from the logs you see above. You should have an interface of notebook.
Check the demo notebook’s code to play with SQL queries on TiDB:
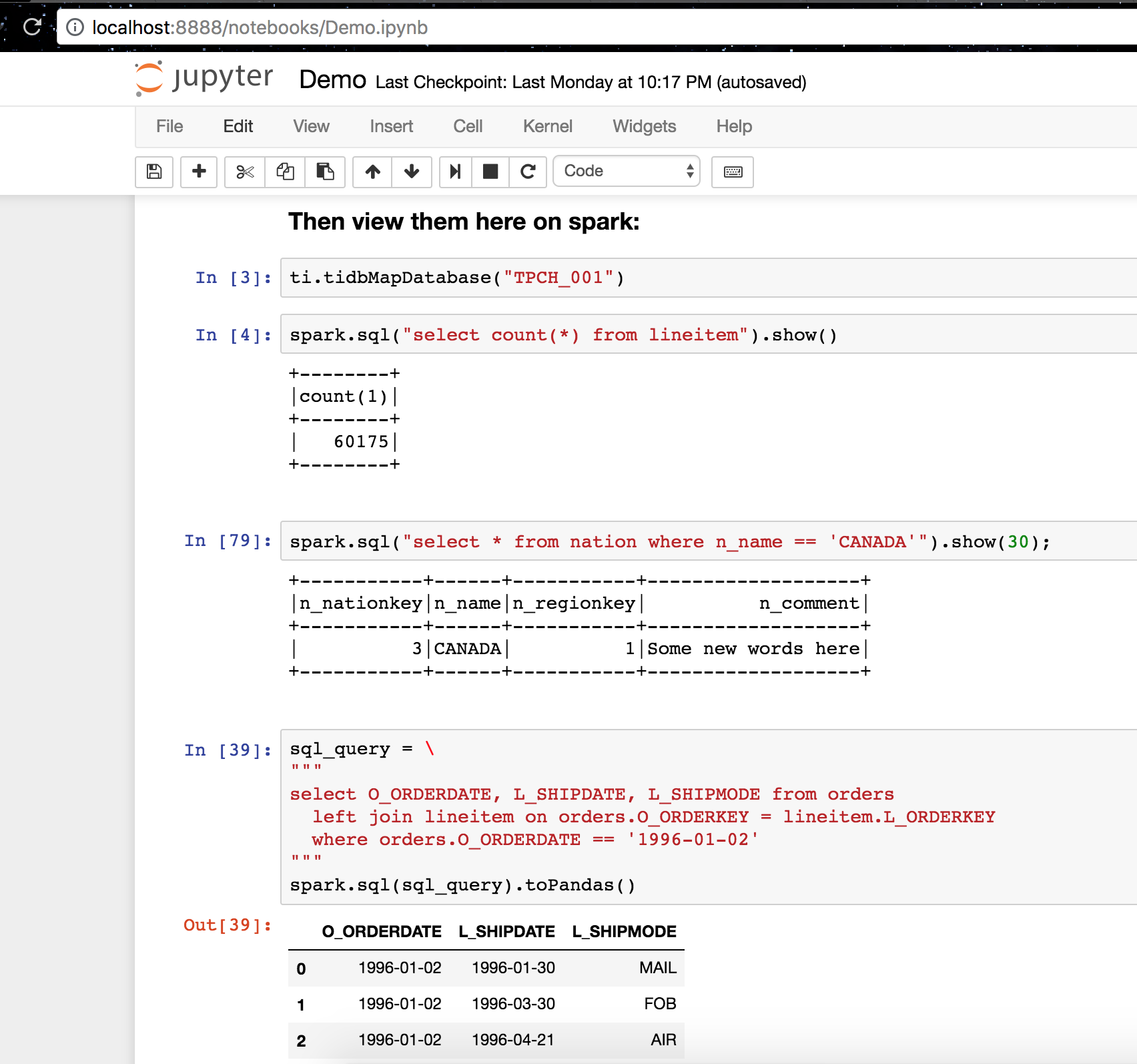
So now you have deployed TiDB cluster with TiSpark at a local docker environment and can try query with it.
However to truly use utilise the benefit of distributed computing, we will have to move on to deploy TiDB onto a cluster which has multiple nodes/machines.
We will try to do that in Part 2, perhaps using Kubernetes as the cluster operator. TiDB team is now working on a solution called Ti-Operator dedicated for spin up TiDB clusters on Kubernetes environment. We will wait and see if that can help us easily achieve that.
For now, you may want to take a look at this: https://banzaicloud.com/blog/tidb-kubernetes/